In diesem Kapitel werden die wesentlichen Basiskonzepte und Begriffe betrachtet, die sich aus einer theoretisch-analytischen Betrachtung des Themas ergeben.
Quellmodell/Zielmodell (Source Model/Target Model)
Eine Modelltransformation, die mit dem M2M SDK ausgeführt wird, überführt Inhalte und Strukturen eines Quellmodells in Inhalte und Strukturen eines Zielmodells. Das Quellmodell enthält somit die vorhandenen Inhalte in der Ausgangsstruktur und das Zielmodell soll die zu erzeugenden Inhalte in der zu erzeugenden Struktur beinhalten. Da neu erzeugte Inhalte sofort persistiert werden, ist es erforderlich, dass Quell- und Zielmodell stets verschieden sind, da sonst eventuell die Terminierung nicht gegeben ist.
Im einfachsten Fall liegt lediglich ein Kopiervorgang vor, d.h. Quell- und Zielmodell besitzen die gleiche Struktur und die Informationen werden unverändert vom Quell- in das Zielmodell übertragen, wobei die Übertragung auch nur selektiv geschehen kann.
Voraussetzung hierfür ist, dass Quell- und Zielmodell als Graphen beschreibbar sind, die nach einem definierten Metamodell, das selbst wieder als Graph beschreibbar ist, strukturiert sind.
Dies trifft z.B. zu für UML2-Modelle, Entity-Relationship- bzw. Structured-Entity-Relationship-Modelle, XML-Dateien, die nach einem definierten XML-Schema aufgebaut sind, BPMN-Modelle und Modelle der Geschäftsprozessmodellierung auf Basis UML2 (GP-Modelle).
Des Weiteren werden nur gültige Modelle transformiert, also solche, die dem Metamodell genügen, auf dessen Basis sie definiert wurden. Es sind also insbesondere keine Modelle erlaubt, die den Existenzabhängigkeiten des Metamodells nicht genügen. Beispiele für ungültige Modelle wären ein UML2-Modell, das Assoziationskanten ohne Vorhandensein der zugehörigen Klassen an den Enden der Assoziation besitzt oder ein Modell, das "in der Luft hängende" Kanten besitzt.
In der Regel werden Quell- und Zielmodell Innovator-Modelle sein, doch können auch Innovator-externe Modelle transformiert werden, vorausgesetzt, dass das jeweilige Metamodell in das M2M SDK integriert wurde oder integriert wird. Dafür können Arbeiten in der Rolle SDK-Entwickler erforderlich sein.
Um ein neues Metamodell in das M2M SDK zu integrieren, sind grundsätzlich folgende Schritte erforderlich:
- Implementieren einer Spezialisierung der Klasse MetaModel
- Das Metamodell liefert alle Modellelemente des Modells.
- Das Metamodell kennt alle unterstützten PropertyDescriptors. Ein PropertyDescriptor beschreibt die Eigenschaften eines Modellelements auf der Ebene des Metamodells.
- Implementieren einer Spezialisierung der Klasse MappingModel
- Das Mappingmodell enthält die Modellelemente von Quell- und Zielmodell. Wenn das Metamodell von Quell- und Zielmodell verschieden ist, ist je eine Implementierung von MappingModel für Quell- und Zielmodell erforderlich.
- Implementieren einer Spezialisierung der Klasse MappingElementBaseImpl
- Diese leistet lesenden und schreibenden Zugriff auf den Eigenschaften eines Modellelements.
- Eventuell notwendige, zusätzliche Spezialisierungen für Einbettungen, Suchen, Produktionen usw.
Relationenmodell (Relation Model)
Ein großer Vorteil der Modelltransformation mit dem M2M SDK ist die Möglichkeit, zwischen den Modellelementen des Quellmodells und den Modellelementen des Zielmodells persistente Beziehungen herzustellen, weil dadurch eine Navigierbarkeit (Traceability) zwischen Elementen von Quellmodell und Zielmodell gegeben ist. Die Menge dieser persistenten Beziehungen bilden ein eigenes Modell, das Relationenmodell genannt wird. Die Beziehungen selber werden als Kleber (Glue) bezeichnet.
Morphismus (Morphism)
Der Begriff des Morphismus ist zentral für das Gebiet der Modelltransformation mit dem M2M SDK.
Die Theorie der algebraischen Graphtransformation setzt auf dem Begriff des Graph-Homomorphismus auf. Dieser ist definiert als eine Abbildung zwischen Graphen, die dadurch gekennzeichnet ist, dass Knoten auf Knoten und Kanten auf Kanten abgebildet werden, was in den meisten Anwendungen grundsätzlich gegeben ist. Es handelt sich also um eine im weitesten Sinne strukturverträgliche Abbildung zwischen Graphen.
In der Begriffswelt des M2M SDK ist ein Modellmorphismus oder kurz Morphismus definiert als Abbildung, die ein gültiges Modell a mit dem Metamodell A auf ein gültiges Modell b mit dem Metamodell B abbildet. Dabei ist zu berücksichtigen, dass auch gültige Teilmodelle von Modellen mit in Betracht gezogen werden.
Morphismen sind zu unterscheiden von Funktionen, die zur Berechnung skalarer Werte wie z.B. Zeichenketten oder boolescher Werte, z.B. für Einschränkungen, benötigt werden.
Modelltransformation (Model Transformation)
Eine Modelltransformation innerhalb des M2M SDK ist eine frei konfigurierbare und fest definierte Sequenz einzelner Modelltransformationsschritte.
Jeder Modelltransformationsschritt (Model Transformation Step) kann mit zusätzlichen Anwendungsbedingungen beziehungsweise Einschränkungen (Application Conditions) und einer Einbettung der transformierten Modellelemente im Zielmodell versehen werden.
Für das M2M SDK gilt die Beschränkung, dass die Berechnung des Quellmodells mittels einer Erweiterung der initialen Selektion (Model Extension) nur vor dem ersten Transformationsschritt durchgeführt werden kann, obwohl dies theoretisch für jeden Transformationsschritt möglich wäre. Das bedeutet, dass im M2M SDK das berechnete Quellmodell während der Durchführung einer Modelltransformation für alle Transformationsschritte konstant ist.
Ein Modelltransformationsschritt selbst ist gekennzeichnet durch folgende Elemente:
- Quellmodell, auf dem die Transformation ausgeführt werden soll. Dabei kann das Quellmodell für einen Transformationsschritt ein gültiges Teilmodell Qt sein, berechnet aus der Selektion Qs aus dem zu transformierenden Gesamtmodell QG, wobei Qt für alle Transformationsschritte konstant ist.
- Zielmodell, in das die Transformation erfolgen soll.
- Treffermorphismus (Source Match) respektive Filterfunktion (Filter Function), der QS nach Qt abbildet. Das Ergebnis dieser Abbildung kann durch zusätzliche Anwendungsbedingungen weiter eingeschränkt sein. Der Treffermorphismus ist dadurch gekennzeichnet, dass er in der Selektion QS alle Elemente findet, die einem bestimmten Suchmuster entsprechen (Source Pattern). Es ist Aufgabe des M2M-Konfigurators oder SDK-Entwicklers, dieses Suchmuster zu definieren.
- Treffermorphismus (Target Match), der mit zusätzlichen Einschränkungen (DescriptiveVariationPoint) auf der Seite des Zielmodells definiert, in welche Elemente des Zielmodells die im Quellmodell gefundenen Modellelemente überführt werden sollen.
- Klebermorphismus (Glueing Morphism), der beschreibt, mit welchem Muster für den Kleber die Elemente aus Source und Target Pattern miteinander verbunden werden.
Ein potentieller Modelltransformationsschritt, d.h. die soeben erwähnten Strukturen ohne deren Anwendung auf ein konkretes Quell- und Zielmodell, wird Produktion (Production) genannt.
Einschränkung des Quellmodells (Model Restriction)
Häufiger kann es notwendig sein, die Treffermenge des Suchmusters eines Morphismus in einer Weise einzuschränken, die nicht durch das Muster selber beschreibbar ist.
Hierzu dienen zusätzliche logische Prädikate, die Anwendungsbedingungen (Application Conditions) für den Morphismus genannt werden.
Erweiterung der initialen Quellauswahl (Model Extension)
In vielen Fällen wird der Anwender einer Modelltransformation zur Ausführung der Modelltransformation nur eine Auswahl A, auch als initiale Quellauswahl bezeichnet, der für ihn interessanten Modellelemente vorgeben wollen, ohne dass diese zusammen bereits ein gültiges (Teil-)Modell formen. Modelltransformationen können aber per Definition nur auf gültigen Modellen ausgeführt werden.
In der Regel wird die Erweiterung von A zu einem gültigen Modell nicht in genau einer Art und Weise vorgegeben sein, sondern ist abhängig von der Art der Erweiterung. Diese Erweiterungsart lässt sich formal durch einen Modellmorphismus E beschreiben. E wird als Modellerweiterung (Model Extension) bezeichnet und kann für jeden Transformationsschritt extra angegeben werden. Es ist Aufgabe des M2M-Konfigurators E für den Transformationsschritt zu konfigurieren.
Einbettung (Model Embedding)
Konzept der Einbettung
Wurde eine Transformation auf einem Quellmodell durchgeführt, stellt sich in der Regel die Frage, wie das transformierte Quellmodell in das Zielmodell eingefügt werden soll. Hierzu dient ein Morphismus, der Modelleinbettung (Model Embedding) genannt wird. Eine Einbettung beschreibt, wie die Verknüpfung zwischen Quell- und Zielmodell vorgenommen werden soll und ist formal ein Morphismus vom Quell- in das Zielmodell, wobei das Quellmodell in diesem Fall das transformierte Modell ist.
Die Modelleinbettung kann als zur Modellerweiterung inverse Operation angesehen werden.
Ankerpunkte
Ankerpunkte sind das Konzept, um Einbettungen innerhalb des M2M SDK definieren und berechnen zu können und zwar dergestalt, dass damit Modellelemente des Quellmodells als Einbettung für das Source Match definiert werden können und Modellelemente des Zielmodells als Einbettung für das Target Match. Als Existenzvoraussetzung müssen die Modellelemente, die die Einbettung im Quellmodell definieren, bereits transformiert worden sein, so dass über das Relationenmodell von einem Ankerpunkt im Quellmodell zu einem Ankerpunkt im Zielmodell navigiert und von dort das fragliche Element innerhalb des Target Match eingefügt werden kann.
Noch einmal der Algorithmus in Kurzform:
- Navigation vom fraglichen Element e im Quellmodell zu einem anderen Element e' im Quellmodell (Ankerpunkt Quelle)
- Mittels Relationenmodell Navigation zu et' im Zielmodell (Ankerpunkt Ziel)
- Relativ zu et' Einbettung des neu erzeugten Elements et gemäß Target Pattern
Abbildung: Einbettung neu erzeugter Elemente
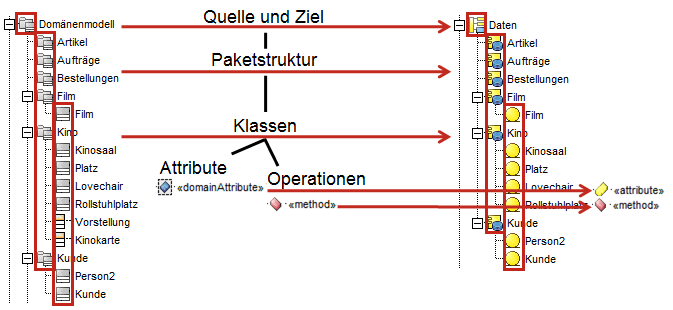
Im Bild werden die Pakete in das Modell eingebettet. Die Klassen werden in ihr Paket eingebettet und die Attribute und Operationen werden in ihre Klasse eingebettet.
Kleber (Glue)
Konzept der Kleber
Ein Kleber (Glue) ist eine Verknüpfung zwischen Elementen des Quellmodells und Elementen des Zielmodells, um nach Ausführung der Modelltransformation feststellen zu können, aus welchen Elementen des Quellmodells bestimmte Elemente des Zielmodells hervorgegangen sind und damit die Modelltransformation bei bereits bestehenden oder auch unabhängig vom Quellmodell geänderten Zielmodell erneut ausführen zu können.
Virtuelle vs. Persistente Glues
In der Welt des M2M SDK wird zwischen virtuellen und persistenten Klebern unterschieden.
Virtuelle Kleber sind solche, die alleine auf der Basis eines funktionalen Zusammenhangs bestehen, z.B. Namensgleichheit von Klassenattributen, aber bei Änderung dieses Zusammenhangs verloren gehen. Dieser Zusammenhang kann auch durch weitere Merkmale an den Modellelementen in Quelle und Ziel erreicht werden, z.B. eine ID, die durch das TargetMatch gesucht und gepflegt wird. Dies ist jedoch nicht Teil des Glueing Morphism.
Persistente Kleber sind solche, die als eigenständige Informationseinheiten persistiert werden. Eine UML2-Dependency wird z.B. gelöscht, wenn das Quellelement der Dependency gelöscht wird.
Variationspunkte (Variation Points)
Konzept der Variationspunkte
Das ursprüngliche Konzept des Patterns innerhalb der algebraischen Graphtransformation ist "starr", d.h. es würde stets eine ganz bestimmte Konstellation von Knoten und Kanten damit gefunden. Es wird also die Voraussetzung gemacht, dass Knoten und Kanten abgesehen von ihrer Anordnung innerhalb eines Graphen prinzipiell ununterscheidbar sind.
In realen Modellen haben Knoten und Kanten jedoch Eigenschaften, die in die Definition von Mustern mit einfließen sollen. Die Ausprägungen dieser Eigenschaften sind unter Umständen erst während der Ausführung der Modelltransformation bekannt, so dass es notwendig sein kann, die konkrete Ausprägung eines Musters erst zur Laufzeit zu berechnen.
Zu dem Zweck wurde im M2M SDK das Konzept der Variationspunkte (Variation Points) eingeführt, das es erlaubt, ein Muster als Schablone zu definieren, aus der erst zur Laufzeit das eigentliche Muster berechnet wird, aus dem sich eine konkrete Treffermenge ergibt.
Beschreibende Variationspunkte
Beschreibende Variationspunkte (Descriptive Variation Points) sind Prädikate, die eine Menge von Modellelementen bezüglich einer bestimmten Eigenschaft erfassen. Beschreibende Variationspunkte werden zum Einschränken des Quellmodells und zur Suche des Modellelements im Zielmodell verwendet.
Funktionale Variationspunkte
Funktionale Variationspunkte (Functional Variation Points) verwenden Implementationen skalarer Funktionen, um Muster zu berechnen und werden bei der Pflege des Modellelements im Zielmodell eingesetzt. Diese Funktionen verwenden das Modellelement im Quellmodell als Eingabe. Ein Beispiel wäre die Berechnung des Namens einer Klasse in einem UML-2-Modell als Zielmodell gemäß bestimmter Konventionen aus dem Namen der zu transformierenden Klasse im Quellmodell.
Transformationsalgorithmus
Der Algorithmus der Modelltransformation umfasst pro Transformationsschritt folgende grundlegende Schritte:
- Erweitere die initiale Auswahl des Benutzers (Model Extension)
- Bestimme die Treffermenge für den aktuellen Transformationsschritt (Source Match)
- Finde das Ziel mittels Kleber (Glue Match). Wenn gefunden, weiter bei 6.
- Bestimme im Ziel die Einbettung des Modellelements (Match Embedding)
- Finde das Ziel über seine Eigenschaften (Target Match)
- Bette das Zielelement im Ziel zur Erzeugung ein (Pattern Embedding)
- Erzeuge oder aktualisiere das Ziel (Target Pattern bzw. Production)
- Erzeuge oder aktualisiere den Kleber (Glue Pattern)
