MOF-Standard der OMG
Die Meta Object Facility (MOF) ist ein von der Object Management Group (OMG) propagierter Standard für das Management von Metadaten. Eine ganze Reihe von Technologien, die von der OMG standardisiert werden (darunter UML, IMM, BPMN, Software Process Engineering Metamodel (SPEM) sowie verschiedene UML-Profile) verwenden MOF bzw. daraus abgeleitete Technologien (insbesondere XMI) für den metadaten-orientierten Austausch und die Verarbeitung von Modellinformationen.
4-Schichten-Architekturen für Metadaten
Der klassische Ansatz zur Metamodellierung basiert auf einer 4-Schichten-Architektur. Diese Schichten werden üblicherweise so beschrieben:
- Die "Information"-Schicht enthält die zu beschreibenden Daten aus der "realen Welt". Weil dies die unterste Schicht dieser Architektur ist, wird diese Schicht auch kurz als "M0" (Metaebene 0) bezeichnet
- Die "Model"-Schicht (M1) hat den Zweck, die Informationen aus der realen Welt, also die Daten der darunterliegenden M0-Schicht, geeignet zu beschreiben und zu klassifizieren. Bei den Daten der M1-Schicht handelt es sich also um Metadaten zur Beschreibung der Daten aus der "Information"-Schicht. Die Gesamtheit dieser Metadaten wird deshalb auch als Modell bezeichnet.
- Die "Metamodel"-Schicht (M2) verhält sich zur darunterliegenden M1-Schicht in analoger Weise: ihre Daten beschreiben und klassifizieren die Struktur und Semantik von Informationen eines Modells. Daher spricht man bei den Daten der M2-Schicht konsequenterweise von Meta-Metadaten. Die Gesamtheit dieser Meta-Metadaten wird deshalb auch als Metamodell bezeichnet. Ein Metamodell ist, anders ausgedrückt, eine "abstrakte Sprache", mit der sich verschiedene Arten von Informationen beschreiben lassen. In welcher Form diese Beschreibung zu erfolgen hat, bleibt zunächst offen.
- Die "Meta-Metamodel"-Schicht (M3) verhält sich zur darunterliegenden M2-Schicht in analoger Weise: sie dient der strukturellen und semantischen Beschreibung von Meta-Metadaten. Ein Meta-Metamodell ist also, anders ausgedrückt, eine "abstrakte Sprache", mit der sich verschiedene Arten von Metadaten beschreiben lassen.
Betrachtet man diese 4-Schichten-Architektur aus der anderen Richtung, dann kann man ein Datum aus einer Schicht immer als Exemplar (Instanz) einer Informationseinheit aus der darüber liegenden Schicht begreifen. Diese Beziehung wird häufig mit dem Schlüsselwort "instanceOf" gekennzeichnet.
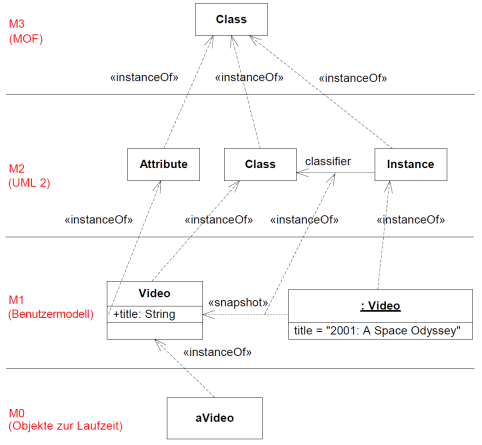
MOF wird von der OMG als standardisierte "Metasprache" benutzt, um andere Modellierungssprachen wie z.B. UML zu spezifizieren. Damit ist MOF ein Standard für die M3-Schicht in 4-Schichten-Architekturen für Metadaten. Den Zusammenhang zum UML-Standard zeigt die folgende Abbildung.
Abbildung: 4-Schichten-Metadaten-Architektur (vgl. UML 2.4.1 Infrastructure, Figure 7.8)
Die MOF-2-Spezifikation hat in vielerlei Hinsicht Ähnlichkeit zur "UML 2 Infrastructure"-Spezifikation, da Teile dieser Spezifikation wiederverwendet worden sind, z.B. die Notation in Form von Klassenmodellen (s.u.), MOF 2 erweitert diese dann hauptsächlich um Konzepte für ein Metadaten-Management.
Überträgt man diese 4-Schichten-Architektur auf die Architektur von Innovator, ergibt sich folgendes Bild:
- Die M3-Schicht ist fester Bestandteil des Innovator-Modellservers und nicht veränderbar.
-
- In der M1-Schicht findet die eigentliche Modellierung statt. Für diese Schicht stehen die Toolfenster, Diagramm- und Tabelleneditoren zur Verfügung, mit denen die Benutzer eines Innovator-Modells arbeiten.
- Die M0-Schicht repräsentiert die reale Welt und ist daher kein typischer Teil eines Modells. Es ist aber zumindest in Innovator for Software Architects möglich, Instanzspezifikationen als eine Art "Objekt" der realen Welt zu modellieren.
Metaklassen, Metaattribute und Metaassoziationen verstehen
Die Meta Object Facility verwendet Klassenmodelle zur Spezifikation von Metamodellen. Um MOF-konforme Metamodelle lesen und richtig interpretieren zu können, reicht es daher im Wesentlichen aus, Klassendiagramme lesen zu können. Die wichtigsten Eigenschaften der Basiskonstrukte Metaklasse, Metaattribut und Metaassoziation, die man dazu kennen sollte, werden in diesem Kapitel vorgestellt.
Metaklasse
Der Zweck einer Klasse besteht darin, Daten aus der darunterliegenden Schicht der Metadaten-Architektur anhand gemeinsamer Merkmale zu klassifizieren. Eine Metaklasse ist daher eine Zusammenfassung gleichartiger Modellelemente unter einem gemeinsamen Oberbegriff, der in Innovator-Modellen auch als "Elementtyp" bezeichnet wird. Eine Klasse wird durch ein Viereck, das "classifier"-Symbol, dargestellt.
Als Beispiel zeigt die folgende Abbildung die beiden Metaklassen "Association" und "Class", die beide Bestandteil des UML-2-Metamodells sind. Diese Metaklassen lassen sich in einem Modell instanziieren: in unserem Beispiel sind die beiden Klassen "Person" und "Car" Instanzen der Metaklasse "Class", und die Assoziation "Person.car" zwischen diesen beiden Klassen ist eine Instanz der Metaklasse "Association".
Abbildung: Beispiel für eine Metamodellierung (vgl. UML 2.4.1 Infrastructure, Figure 7.6)
![]()
Metaassoziation
Eine Assoziation zwischen zwei Metaklassen sagt aus, dass zwei Instanzen der assoziierten Metaklassen (also zwei Metadaten eines Modells) miteinander in Beziehung stehen können.
Ausschließlich zweiwertige (binäre) Assoziationen können Aggregationen darstellen (d.h. eine Teil-Ganzes-Beziehung). In solchen Fällen wird das Assoziationsende, an dem sich die Metaklasse für das "Ganze" befindet, durch eine Raute gekennzeichnet. Ist diese Raute schwarz ausgefüllt, handelt es sich um eine starke Aggregationsbeziehung (Komposition). In diesem Fall gilt: wird von einer Komposition das "Ganze" gelöscht, werden alle "Teile" automatisch ebenfalls gelöscht.
Eine Pfeilspitze an einem Assoziationsende zeigt an, dass es sich um ein navigierbares Assoziationsende handelt. Navigierbare Enden dienen dazu, zur Laufzeit auf Daten auf dieser Seite der Assoziation direkt zugreifen zu können. Beliebig viele Enden einer Assoziation dürfen navigierbar sein. Unabhängig davon dürfen Modellierungswerkzeuge aber auch in der Lage sein, über nichtnavigierbare Assoziationsenden zu navigieren.
Die Teilmengenbildung (Subsetting) ist ein wichtiges mengentheoretisches Konzept, das aber nicht auf die Assoziation selbst, sondern auf deren Assoziationsenden angewendet werden kann. Dieses Konzept besagt, dass die Wertemenge an einem Assoziationsende a, welches ein Subset eines Assoziationsendes b ist, entweder identisch mit der Wertemenge von b ist oder aber eine echte Teilmenge dieser Wertemenge bildet. Teilmengenbildung wird bei der Definition von Metamodell-Erweiterungen verstärkt eingesetzt, um Einschränkungen für Stereotype zu formulieren.
Metaattribut
Ein Metaattribut ist entweder ein Attribut einer Metaklasse oder aber ein Assoziationsende einer Metaassoziation. Der Typ eines solchen Attributs legt fest, welche Werte als Metadaten im Modell zulässig sind.
Die Eigenschaften von Attributen und Assoziationsenden lassen sich durch verschiedene Schlüsselwörter näher spezifizieren:
-
Ist ein solches Assoziationsende als {ordered} gekennzeichnet, dann lässt sich die Wertemenge der Metadaten nach einem gegebenen Sortierkriterium ordnen.
-
Das Schlüsselwort {non-unique} besagt, dass die Wertemenge der Metadaten Duplikate enthalten darf. Fehlt dieses Schlüsselwort, dann sind die Werte der Wertemenge eindeutig voneinander unterscheidbar.
-
Ist ein Attribut als {readOnly} markiert, dann kann ein einmal vergebener initialer Wert nicht nachträglich verändert werden.
-
Ein abgeleitetes Attribut ist daran erkennbar, dass dem Attributnamen ein Schrägstrich ("/name") vorangestellt wird. Bei abgeleiteten Attributen lässt sich der Wert eines solchen Attributs aus anderen Informationen errechnen. Die Berechnungsvorschrift hierfür kann z.B. in Form eines einschränkenden Ausdrucks in der Sprache OCL beschrieben werden.
Abgeleitete Attribute sind häufig als {read-only} markiert (s.o.), so dass der Attributwert nur einmal berechnet und dann nicht mehr verändert wird.
- Eine abgeleitete Assoziationsrolle kann zusätzlich durch das Schlüsselwort {union} als abgeleitete Vereinigungsmenge ("derived union") gekennzeichnet werden. Damit wird ausgedrückt, dass die Wertemenge einer als "/<role> {union}" beschrifteten Assoziationsrolle wie folgt errechnet wird:
Betrachtet werden alle Teilmengen (Subsets, s.o.) dieser Assoziationsrolle, also alle Rollen, die mit {subsets <role>} markiert sind.
Aus diesen Teilmengen wird die Vereinigungsmenge gebildet.
Wichtig zu wissen:
Eine Assoziationsrolle a kann nur dann als Teilmenge einer anderen Rolle b gekennzeichnet sein ("a {subsets b}"), wenn seine Wertemenge konform zur Wertemenge der Rolle b ist. In der Regel ist dies der Fall, wenn die mit der Rolle a verbundene Metaklasse eine Spezialisierung der Metaklasse ist, die mit der Rolle b verbunden ist.
Die abgeleitete Vereinigungsmenge einer Assoziationsrolle ist lediglich als allgemeingültige Rechenvorschrift zu verstehen, die tatsächliche Wertemenge hängt von der Anzahl und Größe der nichtabgeleiteten Subsets dieser Assoziationsrolle ab und ergibt sich für jede Metaklasse möglicherweise neu.
