Das vorliegende Dokument beschreibt alle Konzepte, Funktionalitäten und Begriffe des M2M-SDK. Hier werden Einzelheiten über die Möglichkeiten der Konfiguration des M2M-SDKs und der Erweiterung mit neuen Funktionalitäten dargestellt.
2. Voraussetzungen
Das M2M-SDK benötigt die Java SE 6 Runtime Environment. Die Laufzeitumgebung des M2M-SDK besteht aus
allen JAR-Dateien des $(INODIR)/java/M2MSDK/bin Verzeichnisses
allen JAR-Dateien des $(INODIR)/java/M2MSDK/lib Verzeichnisses
allen JAR-Dateien des $(INODIR)/java/ModelCore/bin Verzeichnisses
allen JAR-Dateien des $(INODIR)/java/MappingCore/bin Verzeichnisses
Weitere JAR-Dateien hängen vom Gebrauch des M2M-SDK ab. Wenn Sie Innovator-Modelle verwenden, benötigen Sie auch
$(INODIR)/java/lib/ext/inojapi.jar
3.1 Rollen
Für die Konfigurationsoberfläche benötigen der SDK-Entwickler und der M2M-Konfigurator eine Aktionssequenz mit einer Engineering-Aktion. Der Benutzer der Modelltransformation benötigt eine weitere Aktionssequenz mit einer Engineering-Aktion zum Starten der Modelltransformation. Fügen Sie den entsprechenden Rollen die Aktionssequenz hinzu und fügen Sie die Aktionssequenz auch den entsprechenden Menüs hinzu, damit Sie im Modellbrowser verfügbar ist.
3.2 Location
Vier Anwendungen sind für die M2M-Konfiguratoren zur Verwendung in einer Engineering-Aktion verfügbar: MappingApplication, ConfigurationApplication, MonitorApplication und ServerFactoryApplication.
Die MappingApplication
ist die Mappinganwendung. Sie führt den Ablauf und darin enthaltene
Modelltransformationen aus. Für MappingApplication verwenden Sie de.mid.innovator.m2msdk.application.MappingApplication als Location.
Die ConfigurationApplication
ist die Konfigurationsoberfläche. Sie erlaubt die Konfiguration der
Ablaufsteuerung und der Modelltransformation und das Setzen von Optionen. Für ConfigurationApplication
verwenden Sie de.mid.innovator.m2msdk.application.ConfigurationApplication als Location.
Die ServerFactoryApplication ist die M2M-SDK-Serverfabrik. Sie wartet auf Anfragen von Mappinganwendungen. Für ServerFactoryApplication verwenden Sie de.mid.innovator.m2msdk.application.ServerFactoryApplication als Location. Achten Sie darauf, dass die Einstellung an der Engineering-Aktion für "Auf Beendigung warten" nicht gesetzt ist.
Die MonitorApplication
startet eine Monitoranwendung die die M2M-SDK-Serverfabrik und die
M2M-SDK-Server überwacht. Für MonitorApplication verwenden Sie de.mid.innovator.m2msdk.application.MonitorApplication als Location.
Mehr über die ServerFactoryApplication und MonitorApplication erfahren Sie im Kapitel 12. Verteilte Berechnung.
3.3 Argumente
Sie können alle Optionen als Argumente der Engineering-Aktion verwenden. Verwenden Sie folgendes Format für die Argumente "<Optionsname>=<Optionswert>". Klammern Sie den Optionswert mit doppelten Anführungszeichen, wenn er Leerzeichen enthält. Sie finden eine Liste aller verfügbaren Optionen unter 6.2 Verfügbare Optionen. Sie benötigen zumindest das Argument "Option", das auf eine Optionsdatei verweist, die alle anderen Optionen enthält. Die Optionen legen dann wiederum fest, welche Konfiguration, welche Ablaufsteuerung usw. verwendet wird.
Die beiden Argumente, die auf jeden Fall gesetzt werden müssen, sind "INOHOST=$(INOHOST)" und "INODIR=$(INODIR)".
3.4 Arbeitsverzeichnis
Setzen Sie das Arbeitsverzeichnis auf $(INODIR)/java. Wenn Sie einen anderen Eintrag verwenden, müssen Sie den Klassenpfad entsprechend ändern.
3.5 Klassenpfad
Die Pfade im Klassenpfad sind relativ zum
Arbeitsverzeichnis. Sie benötigen im Klassenpfad mindestens folgende Einträge:
./M2MSDK/bin/M2MSDK.jar
./ModelCore/bin/ModelCore.jar
./MappingCore/bin/MappingCore.jar
./MappingDialogTemplates/bin/MappingDialogTemplates.jar
Die folgenden Einträge werden vom Programm zur Laufzeit zum Klassenpfad hinzugefügt:
./M2MSDK/lib/jdom-2.0.2.jar
./M2MSDK/lib/RunCC.jar
./M2MSDK/lib/commons-io-2.4.jar
4.1 Ablaufschritte
Die Mappinganwendung führt die Ablaufschritte der Ablaufsteuerung
aus. Die Konfigurationsoberfläche bietet Ihnen auf dem ersten Reiter die
Ablaufsteuerung an. Die Ablaufsteuerung befüllt das Quellmodell und das
Zielmodell bevor sie die Modelltransformation aufruft. Ebenso wird die Interaktion
mit dem Benutzer, in Form von Dialogen festgelegt
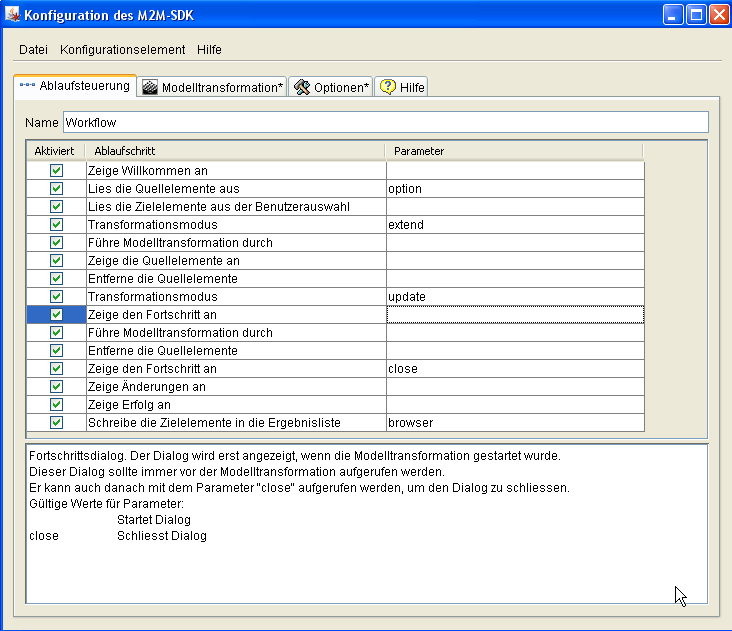
Abbildung 1: Konfigurationsoberfläche (aktiver Reiter: Ablaufsteuerung)
Die Konfiguration wird in der Ablaufsteuerung verwaltet. Die Ablaufschritte werden nacheinander ausgeführt. Die Reihenfolge der Ablaufschritte kann konfiguriert werden. Grundsätzlich ist die Ablaufsteuerung immer in ähnlicher Weise aufgebaut:
- Befüllen der initialen
Auswahl für Quelle und Ziel
Ablaufschritt
1: Lies die Quellelemente aus der Benutzerauswahl
Ablaufschritt 2: Lies die Zielelemente aus der Benutzerauswahl
2. Erweiterung der Quelle anhand der initialen Auswahl mit Anzeige der zu transformierenden Elemente.
Ablaufschritt 3: Setze den Transformationsmodus
Ablaufschritt 4: Führe Modelltransformation durch
Ablaufschritt 5: Zeige Quellelemente an
- Vorschau der Transformation
Ablaufschritt 6: Setze den Transformationsmodus
Ablaufschritt 7: Entferne die Quellelemente
Ablaufschritt 8: Lösche die Protokolleinträge
Ablaufschritt 9: Führe Modelltransformation durch
Ablaufschritt 10: Zeige Änderungen an
(An dieser Stelle
wäre ein Abbruch noch durch den Benutzer möglich)
- Ausführung der Transformation
Ablaufschritt 11: Zeige den
Fortschritt an
Ablaufschritt 12: Setze den
Transformationsmodus
Ablaufschritt 13: Lösche die Protokolleinträge
Ablaufschritt 14: Entferne die Quellelemente
Ablaufschritt 15: Führe
Modelltransformation durch
- Visualisieren der Information für den Benutzer
Ablaufschritt 16: Zeige Protokoll
an
Es gibt vier Typen von
Ausführungsschritten: Dialoge, Clientaufgaben, Serveraufgaben und das Setzen
von Optionen.
4.2 Clientaufgabe
Eine Clientaufgabe benötigt
Zugriff auf den Clientrechner, z.B. Dateizugriff, Umgebungsvariablen, Zugriff
zum Innovator Modellbrowser. Ein Beispiel für eine solche Aufgabe ist "Schreibe Optionen",
der die Optionswerte in eine lokale Datei schreibt.
4.2.1 Lies die Quellelemente aus
Der Inhalt des Quellmodells wird aus der temporären Datei (file), aus der Option oder aus der Zwischenablage (clipboard) gelesen. Die temporäre Datei liegt im temporären Verzeichnis. Das temporäre Verzeichnis wird mit dem Argument "TemporaryDirectory" übergeben. Die Option "SourceFileURI" enthält die URI der Datei mit Modellreferenzen. Die Option "SourceURI" enthält das URI eines Modellelements.
Gültige Werte für Parameter:
file Lese aus Datei
clipboard Lese aus Zwischenablage
option Lese aus der Option
4.2.2 Lies die Quellelemente aus Benutzerauswahl
Der Inhalt des initialen Innovator-Quellmodells wird aus der Selektion im Modellbrowser gelesen.
4.2.3 Lies die Zielelemente aus
Der Inhalt des Zielmodells wird aus einer Datei (file) oder aus der Zwischenablage (clipboard) gelesen. Die Datei liegt im temporären Verzeichnis. Das temporäre Verzeichnis wird mit der Option "TemporaryDirectory" übergeben. Die Option "TargetFileURI" enthält das URI der Datei mit Modellreferenzen. Die Option "TargetURI" enthält das URI eines Modellelements.
Gültige Werte für Parameter:
file Lese aus Datei
clipboard Lese aus Zwischenablage
option Lese aus der Option
4.2.4 Lies die Zielelemente aus Benutzerauswahl
Der Inhalt des initialen Innovator-Zielmodells wird aus der Selektion im Modellbrowser gelesen.
4.2.5 Lies die Optionen aus der Datei
Der Inhalt des Optionsmodells wird aus einer benutzerspezifischen Datei befüllt. Die Datei wird im temporären Verzeichnis gesucht. Das temporäre Verzeichnis wird mit der Option "TemporaryDirectory" übergeben.
4.2.6
Lösche
die Protokolleinträge
Löscht die Protokolleinträge.
Gültige Werte für Parameter:
change löscht die Änderungsnachrichten
4.2.7 Entferne die Quellelemente
Entfernt die Elemente aus dem Quellmodell. Es wird entweder die aktive oder die passive oder beide
Auswahlen gelöscht, aber nie die initiale Auswahl.
Gültige Werte für Parameter:
active löscht die aktive Auswahl
passive löscht die passive Auswahl
löscht aktive und passive Auswahl
4.2.8 Schreibe die Optionen in eine Datei
Der Inhalt des Optionsmodells wird in eine benutzerspezifische Datei geschrieben. Die Datei liegt im temporären Verzeichnis. Das temporäre Verzeichnis wird mit der Option TemporaryDirectory übergeben.
4.2.9 Schreibe die Quellelemente in
Der Inhalt des Quellmodells wird in eine Datei (file) oder in die Zwischenablage (clipboard). Die Datei liegt im temporären Verzeichnis. Das temporäre Verzeichnis wird mit der Option TemporaryDirectory übergeben.
Gültige Werte für Parameter:
file Schreibe in Datei
clipboard Schreibe
in Zwischenablage
4.2.10 Schreibe die Quellelemente in die Ergebnisliste
Der Inhalt des Innovator-Quellmodells wird in die Ergebnisliste des Modellbrowser geschrieben.
4.2.11 Schreibe die Zielelemente in
Der Inhalt des Zielmodells wird in eine Datei (file) oder in die Zwischenablage (clipboard). Die Datei liegt im temporären Verzeichnis. Das temporäre Verzeichnis wird mit der Option "TemporaryDirectory" übergeben.
Gültige Werte für Parameter:
file Schreibe in Datei
clipboard Schreibe in Zwischenablage
4.2.12 Schreibe die Zielelemente in die Ergebnisliste
Der Inhalt des Innovator-Zielmodells wird in die Ergebnisliste des Modellbrowser geschrieben.
4.3 Serveraufgabe
Eine Aufgabe auf dem
Serverrechner benötigt normalerweise intensiven Zugang zum Innovator
Repositoryserver. Die "Modelltransformation durchführen" ist ein
Beispiel für eine Serveraufgabe. Sie implementiert die Modelltransformation.
4.3.1 Führe Modelltransformation durch
Durchführung der Modelltransformation im Server. Die Voraussetzung für diesen Ablaufschritt ist ein gefülltes Quell- und Zielmodell. Sie können die Modelle in der Ablaufsteuerung füllen. Die Modelltransformation wird vom Transformationsmodus (Option "TransformationMode") beeinflusst. Die Konfiguration der Modelltransformation erfolgt auf der Registerkarte "Modelltransformation".
4.4 Optionen setzen
Das Setzen von Optionen beeinflusst alle nachfolgenden Ablaufschritte und Dialoge, z.B. wenn die Option "ShowDialog "auf "false" gesetzt wird, werden keine weiteren Dialoge mehr angezeigt. Meist ist es jedoch ausreichend, den Optionswert während des gesamten Ablaufs gleich zu belassen. Dann sollte die Definition im Reiter "Optionen" erfolgen.
Beispiel:
Transformationsmodus
Dialoge anzeigen?
4.5 Dialoge
Alle Dialoge sind wie die
Seiten eines Assistenten aufgebaut. Zwischen den Dialogen kann der Benutzer mit
"Zurück" und "Weiter" navigieren. Dabei werden alle Ablaufschritte
erneut ausgeführt. "Zurück" macht also nichts rückgängig und der M2M-Konfigurator
muss selbst entsprechende Ablaufschritte einfügen, um z.B. sicherzustellen,
dass das Protokoll zurückgesetzt wird oder dass das Quellmodell leer ist. Der
Benutzer kann jederzeit mit "Abbrechen" den Assistenten beenden. Die
Dialoge sind modal. Vor einer Serveranwendung heißt der "Weiter"
"Start".
In Dialogen muss der Benutzer aktiv werden, indem er mindestens den Dialog mit "Weiter" bestätigen muss. Oftmals kann er aber auch Auswahlen vornehmen. Die Ausnahme ist der Fortschrittsdialog der geschlossen wird, wenn die asynchron laufende Serveranwendung beendet wurde. Wenn die Option ShowDialog den Wert false hat, werden die Dialoge nicht angezeigt.
4.5.1 Zeige Willkommen an
Der Willkommensdialog sollte der erste Dialog sein.
4.5.2 Zeige die Quellelemente an
Anzeige der Modellelemente im Quellmodell. Es wird die initiale, die aktive und die passive Auswahl angezeigt. D. h. es werden auch alle Elemente angezeigt, um die die initiale Auswahl durch die Modellerweiterungen erweitert wurde. Die Modellerweiterungen für abhängige Schritte wirkt hier nicht, da sie nur im Kontext des übergeordneten Schritts gilt! Die Anzeige der Quellelemente macht nur nach der Ausführung der Modelltransformation (meist im Transformationsmodus extend) Sinn.
4.5.3 Zeige Dateiauswahldialog an
Dialog, um eine Datei zum Öffnen oder Speichern
auszuwählen. Die URI der ausgewählten Dateien werden in die Optionen SourceFileURI und TargetFileURI
eingetragen. Über die Option StartFolder wird das
Verzeichnis gesetzt, in dem die Dateiauswahl starten soll.
Gültige Werte für Parameter:
open Öffnen einer Datei
save Speichern einer Datei
4.5.4 Zeige den Fortschritt an
Fortschrittsdialog. Der Dialog wird erst angezeigt, wenn die
Modelltransformation gestartet wurde. Dieser Dialog sollte immer vor der
Modelltransformation aufgerufen werden. Er kann auch danach mit dem Parameter
"close" aufgerufen werden, um den Dialog zu schließen.
Gültige Werte für Parameter:
Startet Dialog
close Schliesst Dialog
4.5.5 Zeige Protokoll an
Anzeige des Protokolls
4.5.6 Zeige Änderungen an
Anzeige der Änderungen an Modellelementen.
Gültige Werte für Parameter:
Durchgeführte Änderungen
pre Vorschau der Änderungen
4.5.7 Zeige Konflikte an
Anzeige der während der Modelltransformation aufgetretenen Konflikte.
Mit Hilfe dieser Anzeige können Sie die Konflikte lösen.
4.5.8 Zeige den Erfolg an
Erfolgsdialog
4.6 Erweiterbarkeit
Der Entwickler kann neue Ablaufschritte hinzufügen. Die neuen Klassen müssen registriert werden. Neue Optionen stehen automatisch auch in der Ablaufsteuerung zur Verfügung. Die Ablaufsteuerung wird in einer XML-Datei gespeichert und kann auch in einem XML-Editor bearbeitet werden. Das zugrundeliegende Schema ist in der Datei $(INODIR)/java/M2MSDK/configuration/de/mid/Workflow.Configuration.Default. xml zur Validierung verfügbar. Die zu implementierende Schnittstelle für Clientanwendungen ist ApplicationInterface, für Serveranwendungen EngineInterface und für Dialoge FrameInterface. Für Dialoge empfiehlt sich die Basisklasse WizardHorizontalFrame. Davon unabhängig müssen die Klassen beim TypePool mit dem zugrundliegenden WorkflowInterface registriert werden.
5.1 Grundlegende Konzepte und Begriffe
5.1.1
Quellmodell und Zielmodell
Die Modelltransformation bildet
das Quellmodell auf das Zielmodell ab. Das Quellmodell beinhaltet alle
Modellelemente, die als Quelle in der Modelltransformation verwendet werden. In-place
Transformation wird nicht unterstützt, weil das Quellmodell während der
Transformation nicht verändert werden sollte, das Zielmodell aber verändert
wird. Dadurch ist das Beenden der Transformation nicht gewährleistet. Bidirektionales
Mapping wird nicht unterstützt, jedes Mapping hat eine Richtung mit Quelle und
Ziel. Das Mapping für die andere Richtung muss separat definiert werden. Das
Quellmodell besteht aus der aktiven und der passiven Auswahl. Die Modellemente
aus der aktiven und passiven Auswahl werden abgebildet, jedoch werden für
Modellelemente in der passiven Auswahl keine Modellelemente im Zielmodell angelegt.
Sie dienen lediglich zur Verwendung in anderen Modellelementen, wie z.B. als Besitzer,
Typ oder assoziierte Klasse. Die initiale Auswahl des Quellmodells und die
initiale Auswahl des Zielmodells können unabhängig voneinander befüllt werden
mit den Clientanwendungen SourceReader, TargetReader, SourceReaderInnovator oder
TargetReaderInnovator. Sie benutzen die Auswahl des Benutzers im Innovator
Modellbrowser oder Die Zwischenablage oder Optionen oder Dateien, in denen die
Modellelemente oder Referenzen auf die Modellelemente enthalten sind. Sie
speichern die Modellelemente in der initialen Auswahl des Quell- bzw.
Zielmodells. Der Inhalt der aktiven und passiven Auswahl kann mit der
Clientanwendung SourceCleaner entfernt werden, um bei erneuter Ausführung gleiche
Ergebnisse zu erhalten. Die Modellelemente des Quellmodells befinden sich in
einer von drei Auswahlen:
|
Initiale Auswahl |
Die initiale Auswahl wird durch einen Ablaufschritt in der Ablaufsteuerung gefüllt. Sie sollte vor der Modelltransformation gefüllt sein. Modellelemente in der initialen Auswahl werden erst abgebildet, wenn sie in die aktive, oder passive Auswahl übernommen werden. |
|
Aktive Auswahl |
Alle Elemente, die sich in der aktiven Auswahl befinden, werden bearbeitet. Die aktive Auswahl ergibt sich aus der initialen Auswahl (dabei handelt es sich um die Elemente, die man bei dem Start der Selektion mitbringt). |
|
Passive Auswahl |
Alle Elemente, die man zur Abbildung benötigt, jedoch werden sie selbst nicht abgebildet. Die passive Auswahl bezeichnet Modellelemente, die für die Modelltransformation als Ankerpunkt verwendet werden. Jedes Modellelement aus der passiven Auswahl kann als Ankerpunkt verwendet werden, wenn es einen Transformationsschritt gibt, der das Modellelement berücksichtigt. |
5.1.2 Kleber
Die Modelltransformation
benutzt Kleber, um zu einem Modellelement im Quellmodell das zugehörige
Modellelement im Zielmodell zu finden. Dies erlaubt die Abbildung in ein bestehendes
Modell. Ein Kleber ist ein Modellelement im Relationenmodell, der ein
Modellelement im Quellmodell mit mehreren Modellelementen im Zielmodell verbunden
ist. Die Kleber im Relationenmodell können persistent sein oder virtuell.
Ein Beispiel für persistente
Kleber ist in einem UML-Modell eine Abhängigkeit oder eine Mapping-Abhängigkeit
in einem Innovator-Modell oder ein Hyperlink in einer HTML-Datei oder ein Innovator
Proxy-Element. Ein persistenter Kleber wird normalerweise während des Laufs der
Modelltransformation erzeugt und bei einem weiteren Lauf verwendet. Er kann
aber auch manuell vom Benutzer angelegt werden, um der Modelltransformation
mitzuteilen, dass die verklebten Modellelemente aufeinander abzubilden sind.
Ein virtueller Kleber
existiert nur zur Laufzeit der Modelltransformation. Sie können daher nicht verwendet
werden, um zu einem Modellelement die Abbildung zu finden, sondern nur um bereits
abgebildete Modellelemente erneut abzubilden. Ein virtueller Kleber ist immer
mit dem Schritt qualifiziert, der ihn erzeugt hat. Ein Beispiel für Kleber, die
nur virtuell sind, sind Namensgleichheit zwischen Modellelementen im
Quellmodell und Zielmodell oder wenn der Bezeichner eines Modellelements im
Quellmodell in einem Modellelement im Zielmodell referenziert ist.
Der virtuelle Kleber entsteht
dadurch, dass ein Modellelement des Quellmodells auf ein Modellelement des
Zielmodells abgebildet wird. Jeder Schritt der Modelltransformation legt
virtuelle Kleber zwischen dem Quellmodellelement und den zugeordneten
Modellelementen im Zielmodell an. Auch zu persistenten Klebern werden virtuell
im Relationenmodell angelegt.
Durch die Wahl des Klebers können Sie das Verhalten der Modelltransformation bestimmen. Der einfachste Kleber ist über Namensgleichheit. Sobald sich jedoch im Quellmodell ein Name ändert, wird das bereits angelegte Modellelement im Zielmodell nicht wiedergefunden. Wenn Sie eine Abhängigkeit als persistenten Kleber verwenden, können Sie nicht verfolgen, ob ein Modelelement im Quellmodell gelöscht wurde, weil die Abhängigkeit mit gelöscht wird. Wenn Sie einen Proxy verwenden, können Sie auch feststellen, ob ein Modellelement im Quellmodell gelöscht wurde und entsprechend zum Beispiel das Modellelement im Zielmodell ebenfalls löschen. Wenn Sie eine Mapping-Abhängigkeit verwenden, können Sie feststellen, dass das Modellelement im Ziel eine Abhängigkeit hatte, obwohl die Mapping-Abhängigkeit selbst beim Löschen des Modellelements mit gelöscht wurde.
5.1.3 Einbettung
Die Einbettung ist die Summe der Beziehungen von einem Modellelement im Zielmodell zu anderen Modellelementen im Zielmodell. Die Modelltransformation benutzt die Einbettung zur Suche von vorhandenen Modellelementen und zum Anlegen von neuen Modellelementen. Die Einbettung ist enthält eine Menge von Modellelementen im Zielmodell, die Ankerpunkte genannt werden. Die Ankerpunkte werden ausgehend vom abzubildenden Modellelement im Quellmodell bestimmt. Dies erfolgt durch die Navigation im Quellmodell zu einem Modellelement, das bereits abgebildet wurde, dem Wechsel vom Quellmodell zum Zielmodell und der anschließenden Navigation im Zielmodell zum Ankerpunkt. Eine Einbettung ist nur dann notwendig, wenn die Suche oder das Anlegen nicht bereits absolut im gesamten Modell möglich sind. Im Innovator wird zum Anlegen eines neuen Modellelements immer eine Einbettung benötigt.
5.1.4 Transformationsmodus
Der Transformationsmodus
(Option TransformationMode) gibt an, ob die Modelltransformation nur simuliert
werden soll (simulate) oder ob die Modellelemente mit persistenten Klebern
verbunden werden sollen (interconnect) oder ob
Modellelemente im Zielmodell geändert und angelegt werden sollen (update) oder ob ausschließlich die Erweiterung des
Quellmodells berechnet werden soll (extend).
5.2 Konfiguration
Die Konfigurationsoberfläche bietet Ihnen auf dem zweiten Reiter die Modelltransformationskonfiguration an. In der Modelltransformation wird die eigentliche Transformation in Form von Schritten, Aufgaben, Gruppen und weiteren Konfigurationseinträgen definiert.
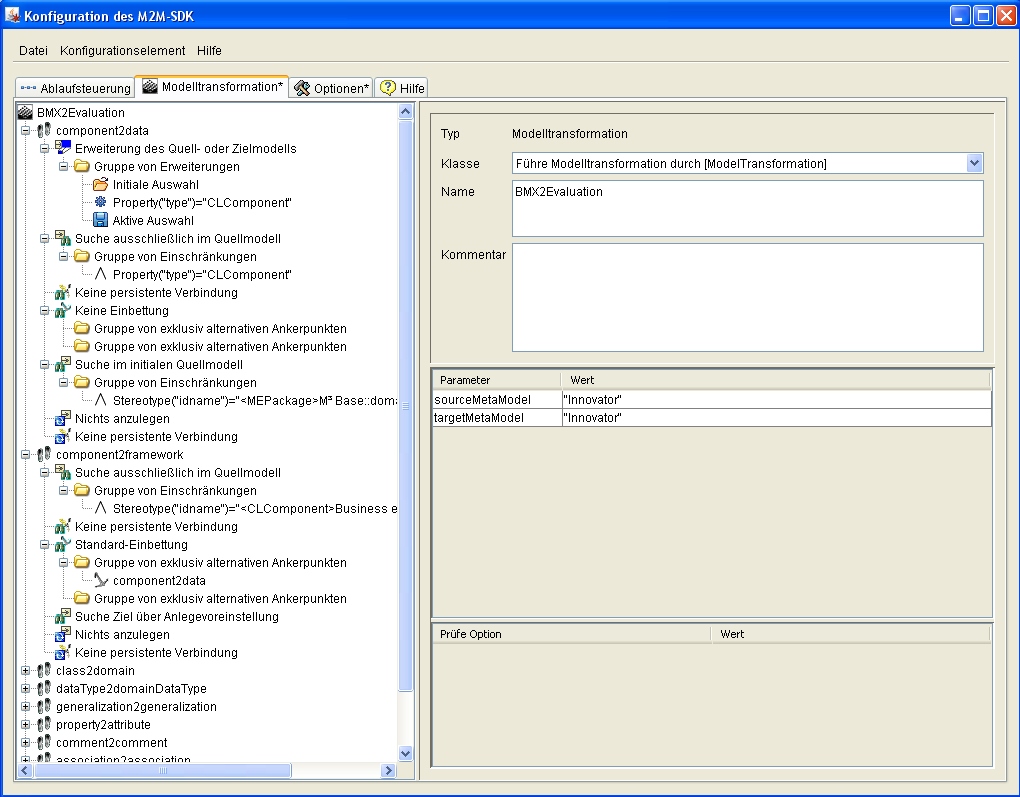
Abbildung 2:Konfigurationsoberfläche (aktiver Reiter: Modelltransformation)
Die Reihenfolge der Schritte kann konfiguriert werden. Die Konfiguration kann in eine XML-Datei gespeichert werden. Die XML-Datei kann auch direkt mit einem XML-Editor bearbeitet werden. Das zugrundeliegende Schema ist in der Datei $(INODIR)/java/M2MSDK/configuration/de/mid/Mapping.Configuration.xsd zur Validierung verfügbar. Das Wurzelelement für die Modelltransformation ist ModelTransformation. Jedes XML-Element hat ein Attribut id, in dem der Bezeichner steht, mit dem es referenziert werden kann. Der Bezeichner ist nur innerhalb seiner Geschwister eindeutig und erst der qualifizierte Bezeichner ist innerhalb des XML-Dokuments eindeutig. Jedes XML-Element hat auch ein Attribut class, das die implementierende Klasse angibt. Der Name des XML-Elements legt die zu implementierende Schnittstelle für die Klasse fest. Attribut comment gibt einen Kommentar des Konfigurators zu diesem Konfigurationselement wieder und das Attribut enabled zeigt an, ob das Konfigurationselement aktiv ist oder nicht. Nicht aktive Konfigurationseinträge werden zum Ausführungszeitpunkt der Modelltransformation ignoriert.
Jeder Konfigurationseintrag kann Parameter besitzen. Welche Parameter an welchem Konfigurationseintrag verfügbar sind, wird durch die implementierende Klasse bestimmt.
Jeder Konfigurationseintrag kann über Optionen gesteuert werden. Wenn zum Ausführungszeitpunkt der Modelltransformation die angegebene Option nicht den angegebenen Wert hat, wird der Konfigurationseintrag ignoriert.
5.3 Konfiguration der Modelltransformation
Sie können ihre eigene Modelltransformation implementieren, indem Sie die Schnittstellen implementieren. Die einzige Klasse, die für die Schnittstelle registriert ist, ist "Modelltransformation".
Symbol: ![]()
Name des XML-Elements: ModelTransformation
Schnittstellen: ModelTransformationIF, EngineInterface
5.4 Gruppierung von Schritten
Jeder Schritt bestimmt, welche Elemente aus der Quelle abgebildet werden, wohin im Zielmodell sie abgebildet werden und welche Eigenschaften sie übertragen. Die Schritte einer Modelltransformation werden sequentiell ausgeführt. Ein Schritt sollte für jedes Modellelement aus der Quelle ein höchstens ein Modellelement im Zielmodell anlegen. Weitere Modellelemente sollten in weiteren Schritten angelegt werden. Die einzige Klasse, die für die Schnittstelle registriert ist, ist "Modelltransformationsschritt".
Symbol: ![]()
Name des XML-Elements: StepGroup
Schnittstelle: StepGroup
Kontext:
- Modelltransformation
5.5 Schritt
Jeder Schritt bestimmt, welche Elemente aus der Quelle abgebildet werden, wohin im Zielmodell sie abgebildet werden und welche Eigenschaften sie übertragen. Die Schritte einer Modelltransformation werden sequentiell ausgeführt. Ein Schritt sollte für jedes Modellelement aus der Quelle ein höchstens ein Modellelement im Zielmodell anlegen. Weitere Modellelemente sollten in weiteren Schritten angelegt werden. Die einzige Klasse, die für die Schnittstelle registriert ist, ist "Modelltransformationsschritt".
Symbol: ![]()
Name des XML-Elements: ModelTransformationStep
Schnittstelle: ModelTransformationStepIF
Kontext:
- Modelltransformation
- Gruppierung von Schritten
5.6 Aufgaben
Jeder
Modelltransformationsschritt besteht aus acht Aufgaben, jede Aufgabe ist ein
Modellmorphismus:
- Erweiterung des Quellmodells
- Quelle bestimmen
- Verbindung suchen
- Einbettung der Suche
- Ziel suchen
- Einbettung fürs Anlegen
- Ziel anlegen und pflegen
- Verbindung anlegen und
pflegen
Die erste Aufgabe wird über
alle Schritte hinweg durchgeführt, so dass das Ergebnis der Erweiterung jedem
Schritt zur Verfügung steht, unabhängig von seiner Position in der Modelltransformation.
Eine Ausnahme bilden die abhängigen Schritte, für die die erste Aufgabe nicht
durchgeführt wird. Als nächstes wird im ersten Schritt das Quellmodell für
diesen Schritt eingeschränkt und dann für jedes Modellelement in der
eingeschränkten Menge die Aufgaben 3 bis 8 ausgeführt. Wenn ein Schritt
abhängige Schritte hat, wird nach der Ausführung von Aufgabe 8 der abhängige
Schritt mit dem Quellmodellelement als initiale Auswahl des Quellmodells
durchlaufen. Die Aufgaben 2 bis 8 werden in gleicher Weise bei jedem weiteren
unabhängigen Schritt wiederholt. Die Bestimmung der Quelle wirkt immer für die
Berechnung des aktuellen Schritts. Sie können für jede dieser Aufgaben eine
eigene Java-Klasse erstellen, indem Sie die angegebene Schnittstelle
implementieren und die Klasse in der Registerklasse am Typenpool registrieren.
5.6.1 Erweiterung des Quellmodells
Die
Erweiterung des Quellmodells soll ausgehend von der initialen Auswahl das
Quellmodell erweitern. Einerseits durch Elemente, die von diesem Schritt
verarbeitet werden sollen, andererseits durch die Elemente, die notwendig sind,
damit dieser Schritt erfolgreich ausgeführt werden kann. Die Erweiterung ist
ein Modellmorphismus, der zu der Menge von Modellelementen im Quellmodell eine
Menge von Modellelementen im Quellmodell findet. Normalerweise wird dabei aus der
Menge der initialen Auswahl die Menge der aktiven und passiven Auswahl
berechnet.
Am Anfang der Erweiterung
sollten die aktive und die passive Auswahl leer sein, damit das Ergebnis
wiederholbar ist. Die initiale Auswahl sollte gefüllt sein. Beides kann durch
entsprechende Ablaufschritte vor der Modelltransformation gewährleistet werden.
Nach Ende der Erweiterung sollte die aktive und passive Auswahl gefüllt sein,
da die weiteren Aufgaben dies als Voraussetzung haben.
Nehmen Sie alle Modellelemente
in die aktive und passive Auswahl auf, die Sie abbilden wollen oder die Sie für
die Abbildung benötigen, z.B. das Paket, in dem die Modellelemente enthalten
sind. Die Erweiterung betrifft das gesamte Quellmodell für alle Schritte bis
auf die abhängigen Schritte. Eine Erweiterung besteht aus Gruppen, in denen die
Anweisungen zusammengefasst sind. Diese Gruppierung ist rein semantisch, um die
Lesbarkeit zu erhöhen. Die einzelnen Anweisungen arbeiten auf dem
Hauptspeicher, der zu Beginn leer ist und mit Modellelementen gefüllt werden
kann. Die Anweisungen führen dabei Mengenoperatoren zwischen dem Hauptspeicher
und weiteren Speichern aus oder sie führen Berechnungen auf den Modellelementen
im Hauptspeicher aus. Weitere Speicher sind die im Kapitel Quellmodell
und Zielmodell erwähnte aktive, passive und initiale Auswahl, vier temporäre
Zwischenspeicher und der Speicher für die Benutzeranzeige. Die Anweisungen
einer Erweiterung werden nacheinander abgearbeitet.
Die einzige Klasse, die für die Schnittstelle registriert ist, ist "Erweiterung des Quell- oder Zielmodells".
Symbol: ![]()
Name des
XML-Elements: SourceExtension
Schnittstelle: ModelExtensionIF
Kontext:
- Schritt
5.6.2 Quelle bestimmen
Aus dem erweiterten
Quellmodell wird in dieser Aufgabe eine Menge von Modellelementen bestimmt, die
in diesem Schritt abgebildet werden. Es ist
ein Modellmorphismus, der aus einer Menge von Modellelementen im Quellmodell
eine Menge von Modellelementen im Quellmodell berechnet. Der Unterschied zur
vorigen Aufgabe ist, dass das Ergebnis nur in diesem Schritt verwendet wird.
Für jedes Modellelement im Ergebnis werden die Aufgaben 3 bis 8 durchgeführt.
Es gibt 4 Klassen, die alle ein anderes Verhalten implementieren.
|
Klasse |
Verhalten |
|
Suche ausschließlich im Quellmodell |
Suche ausschließlich in der aktiven und passiven Auswahl des Quellmodells. Sie können diese Auswahlen in der Ablaufsteuerung füllen oder mit der Quellmodellerweiterung. Die initiale Auswahl wird ignoriert! |
|
Suche im initialen Quellmodell |
Suche im initialen Quellmodell. Sie können diese Auswahl in der Ablaufsteuerung füllen. |
|
Suche im Quellmodell nach Element mit angegebenem Pfad |
Die Suche erfolgt im gesamten Modell. |
|
Suche im Quellmodell nach Element mit angegebener URI |
Die Suche erfolgt im gesamten Modell. |
Das Ergebnis muss den Bedingungen der Klasse entsprechen. Mehrere Bedingungen werden mit ODER logisch
verknüpft. Zusätzlich kann das Ergebnis noch durch zusätzliche Gruppen von Bedingungen
weiter eingeschränkt werden.
Name des XML-Elements: FindSource
Schnittstelle: SourceMatchClassIF
Kontext:
- Schritt
5.6.3 Verbindung suchen
Die Suche ist ein Modellmorphismus, der zu einem
Modellelement im Quellmodell eine Menge von Modellelementen im Zielmodell
berechnet. Für jedes Modellelement in dem für diesen Schritt eingeschränkten
Quellmodell wird ein Ziel über eine Verbindung gesucht. Das Ziel wird dabei anhand
einer bestehenden Verbindung zwischen Quelle und Ziel gesucht, einem
sogenannten persistenten Kleber. Wenn ein Ziel
über eine Verbindung gefunden wird, werden die nächsten beiden Aufgaben übersprungen.
Eine Verbindung kann beim erstmaligen Ausführen der Modelltransformation nur
gefunden werden, wenn Sie zuvor manuell angelegt wurde. Daher ist die
Definition dieser Aufgabe nur dann sinnvoll, wenn ein mehrmaliges Ausführen der
Modelltransformation auf denselben Modellen vorgesehen ist. Wenn mehrere Suchen
vorhanden sind, werden die Ergebnisse von allen Suchen zusammengenommen. Es
gibt 4 Klassen, die alle ein anderes Verhalten implementieren.
|
Klasse |
Verhalten |
|
Abhängigkeit im Innovator |
Innerhalb eines Innovatormodells wird das Ziel über eine Abhängigkeit gesucht. |
|
Innovator zu externem Modell durch Proxy |
Von Innovator in ein anderes Modell wird per Proxy gesucht. |
|
Innovator zu Innovator durch Proxy |
Innerhalb des Innovatormodells wird nach Proxys gesucht. |
|
Keine persistente Verbindung |
Es erfolgt keine Suche über Verbindung. |
Das Ziel muss den Bedingungen der Klasse entsprechen. Zusätzlich kann das Ergebnis noch durch zusätzliche
Gruppen von Bedingungen weiter eingeschränkt werden.
Symbol: ![]()
Name des XML-Elements: FindGlue
Schnittstelle: MappingModelGlueIF
Kontext:
- Schritt
5.6.4 Einbettung der Suche
Es
wird die Einbettung der Suche bestimmt. Diese Bestimmung erfolgt ausschließlich, wenn
die Suche des Ziels über eine Verbindung kein Ergebnis geliefert hat. Wenn
keine Einbettung für das Anlegen definiert wurde, so wird die Einbettung für
die Suche auch fürs Anlegen verwendet. Sie können mehrere Einbettungen angeben,
die alternativ verwendet werden.
Eine
Einbettung besteht aus einer Menge von Modellelementen im Zielmodell, den
sogenannten Ankerpunkten. Die Ankerpunkte bestimmen, wo das Modellelement im
Ziel gesucht werden soll. Die Ankerpunkte werden also durch die Angabe des
Transformationsschrittes bestimmt. Eine Einbettung ist also ein
Modellmorphismus, der zu einem Modellelement im Quellmodell eine Menge von Modellelementen
im Zielmodell berechnet. Diese Berechnung erfolgt über virtuelle Kleber, die
durch vorhergehende Schritte angelegt wurden. Es muss also lediglich definiert
werden, von welchem Schritt der Kleber verwendet wird und wie das Quellelement
des Klebers vom Quellelement des Schrittes erreicht werden kann. Die durch die
Einbettung bereit gestellten Modelellelemente, die sogenannten Ankerpunkte
werden bei der Suche des Ziels in der nächsten Aufgabe verwendet. In welcher
Rolle sie jedoch im Ziel verwendet werden, ist für die Einbettung nicht
relevant.
Zum
Beispiel kann eine Klasse der Ankerpunkt ein Paketes sein, das in einem vorherigen
Schritt abgebildet wurde. Die Rolle des Ankerpunktes wird relativ zum aktuellen
Quellmodell ausgedrückt. Sie können mehrere Ankerpunkte bestimmen. Die
Produktion verwendet den Ankerpunkt, oder die Ankerpunkte, die sie benötigt, unabhängig
von der Einbettung die sie bestimmt hat.
Es stehen acht Klassen zur
Verfügung.
|
Klasse |
Verhalten |
|
Einbettung für Diagrammelemente |
Innerhalb eines Innovatormodells wird das Ziel über eine Abhängigkeit gesucht. |
|
Einbettung für Feature im Fremdschlüssel |
Von Innovator in ein anderes Modell wird per Proxy gesucht. |
|
Einbettung für Feature im eindeutigen Schlüssel oder Indexspalte |
Innerhalb des Innovatormodells wird nach Proxys gesucht. |
|
Einbettung für Fremdschlüssel |
Die Einbettung liefert ein Paar aus dem eindeutigen Schlüssel und der Tabelle oder Entität |
|
Einbettung für Sortierung |
Die Einbettung liefert eine Liste aus dem Besitzer und den enthaltenen Elementen |
|
Keine Einbettung |
Es wird keine Einbettung verwendet. |
|
Mehrfache Einbettung |
Für jeden Ankerpunkt wird eine Einbettung erzeugt. |
|
Standard-Einbettung |
Die Einbettung ordnet alle Ankerpunkte in einer Liste an |
Die Ankerpunkte einer
Einbettung werden über Gruppen von Ankerpunkten definiert.
Für untergeordnete Schritte können Sie das Quellelement des übergeordneten Schritts referenzieren, indem Sie eine besondere Klasse für den Ankerpunkt verwenden. Im ersten Transformationsschritt können Sie mit einer Einbettung nicht auf vorhergehende Schritte referenzieren. Daher ist es sinnvoll auch keine Einbettung zu verwenden, sondern das Ziel ohne Einbettung zu suchen.
Symbol: ![]()
Name des XML-Elements: EmbeddingFind
Schnittstelle: ModelEmbeddingIF
Kontext:
- Schritt
5.6.5 Ziel suchen
Die
Suche ist ein Modellmorphismus, der für jedes Modellelement des eingeschränkten
Quellmodells eine Menge von Modellelementen im Zielmodell bestimmt. Dazu wird
zumeist die Einbettung aus der vorherigen Aufgabe verwendet. Wenn
keine Einbettung für die Suche definiert ist, wird stattdessen die Einbettung
fürs Anlegen verwendet. Das Ziel muss
den Bedinungen entsprechen. Diese Suche wird nur durchgeführt, wenn kein Ziel
anhand der Verbindung gefunden wird. Die Bedingungen werden in den
untergeordneten Gruppen von Bedingungen definiert. Wenn mehrere Aufgaben dieses
Typs definiert sind, werden sie alle ausgeführt und die Vereinigung aller
Ergebnismengen ist die Ergebnismenge.
Es stehen siebzehn Klassen
zur Verfügung.
|
Klasse |
Verhalten |
|
Suche ausschließlich im Zielmodell |
Suche ausschließlich in der aktiven und passiven Auswahl des Zielmodells. Sie können diese Auswahlen in der Ablaufsteuerung füllen oder mit der Ziellmodellerweiterung. Die initiale Auswahl wird ignoriert! Die Parameter "requireOne" und "requireElement" geben zusätzlich an, ob es ein Minimum oder ein Maximum der gefundenen Elemente gibt. |
|
Suche im initialen Zielmodell |
Suche im initialen Zielmodell. Sie können diese Auswahl in der Ablaufsteuerung füllen. Die Einbettung wird bei der Suche ignoriert. Sie können über den Parameter "requireOne" bestimmen, ob höchstens ein Element in der Auswahl sein darf. Sie können über den Parameter "requireElement" bestimmen, ob mindestens ein Element in der Auswahl sein muss. |
|
Nimm Ankerpunkt als Ziel |
Jeder Ankerpunkt könnte ein Ziel sein. Die Ziele können noch eingeschränkt werden. Die Einbettungen können eine beliebige Anzahl von Ankerpunkten enthalten. |
|
Nimm Quelle als Ziel |
Das Quellelement wird als Zielelement verwendet, das heißt das Element wird auf sich selbst abgebildet. |
|
Suche Ziel über Anlegevoreinstellung |
Suche Ziel über Anlegevoreinstellung. Es wird kein Ankerpunkt verwendet. |
|
Suche Ziel über Bezeichner |
Suche Ziel über Bezeichner. Es wird kein Ankerpunkt verwendet. |
|
Suche Ziel über das Mapping-Konfigurationspaket |
Suche Ziel über das Mapping-Konfigurationspaket. Es wird kein Ankerpunkt verwendet. |
|
Suche Ziel über Pfadangabe |
Suche Ziel über Pfadangabe. Es wird kein Ankerpunkt verwendet. |
|
Suche Ziel als Assoziationsende |
Als Ankerpunkte muss als erstes die verbundene Assoziation und zweitens die mit dem Assoziationsende verbundenen Klassifizierer mitgegeben werden. Die Einbettung muss also Paare von Ankerpunkte enthalten. |
|
Suche Ziel als Assoziation |
Als Ankerpunkte müssen die verbundenen Klassifizierer mitgegeben werden. Die Einbettung muß Paare von Ankerpunkte enthalten. |
|
Suche Ziel als Diagramminhalt |
Suche Ziel als Diagramminhalt. Die Einbettung muß Paare von Ankerpunkten enthalten. Ein Ankerpunkt ist ein Diagramm, der andere ist das logische Element eines Diagramminhalts. |
|
Suche Ziel als Fremdschlüssel |
Als Ankerpunkte müssen die verbundenen Entitäten bzw. Tabellen mitgegeben werden. |
|
Suche Ziel mit Besitzer |
Suche ein Modellelement mit der Ankerpunkt als Besitzer und mit dem angegebenen Stereotyp, Typ und Namen. Die Einschränkung auf Stereotyp, Typ und Name können Sie weglassen. Der Ankerpunkt kann auch transitiver Besitzer sein. Dies können Sie über die Parameter "stereotype", "type", "name" und "transitive" steuern. Statt des Parameters "stereotype" können Sie den Stereotyp auch indirekt durch die Anlegeschablone und den Parameter "createTemplate" angeben. Jede Einbettung enthält einen Ankerpunkt, der als Besitzer verwendet wird. |
|
Suche Ziel als Feature im Beziehungsschlüssel |
Suche Ziel als Feature im Beziehungsschlüssel. Als Einbettung benötigen Sie ein Tripel mit dem Fremdschlüssel, dem referenzierten eindeutigen Schlüssel und der referenzierten Spalte oder dem referenzierten Attribut. |
|
Suche Ziel als gerichtete Beziehung |
Suche Ziel als gerichtete Beziehung. Die Einbettung muß Paare von Ankerpunkte enthalten. Die Ankerpunkte sind Quelle und Ziel der Beziehung. |
|
Suche Ziel als Feature im eindeutigen Schlüssel |
Suche Ziel als Feature im eindeutigen Schlüssel oder als Indexspalte. Als Einbettung benötigen Sie Paare mit dem eindeutigen Schlüssel oder Index und einer Spalte oder einem Attribut. |
|
Suche Ziel als From-Klausel |
Als Ankerpunkte müssen die besitzende View und die verwendete Entität, Tabelle oder View mitgegeben werden. |
Das Ziel muss den Bedingungen der Klasse entsprechen. Zusätzlich kann das Ergebnis noch durch zusätzliche
Gruppen von Bedingungen weiter eingeschränkt werden.
Symbol: ![]()
Name des XML-Elements: FindTarget
Schnittstelle: TargetMatchClassIF
Kontext:
- Schritt
5.6.6 Einbettung fürs Anlegen
Die Einbettung fürs Anlegen ist wie eine Einbettung für die Suche definiert. Sie wird nur anders verwendet. Mit Hilfe dieser Einbettung werden Ankerpunkte für das Anlegen eines Modellelements im Zielmodell bestimmt. Wenn mehrere Einbettungen definiert sind, werden die berechneten Ankerpunkte aufgesammelt.
Es stehen acht Klassen zur
Verfügung.
|
Klasse |
Verhalten |
|
Einbettung für Diagrammelemente |
Innerhalb eines Innovatormodells wird das Ziel über eine Abhängigkeit gesucht. |
|
Einbettung für Feature im Fremdschlüssel |
Von Innovator in ein anderes Modell wird per Proxy gesucht. |
|
Einbettung für Feature im eindeutigen Schlüssel oder Indexspalte |
Innerhalb des Innovatormodells wird nach Proxys gesucht. |
|
Einbettung für Fremdschlüssel |
Die Einbettung liefert ein Paar aus dem eindeutigen Schlüssel und der Tabelle oder Entität |
|
Einbettung für Sortierung |
Die Einbettung liefert eine Liste aus dem Besitzer und den enthaltenen Elementen |
|
Keine Einbettung |
Es wird keine Einbettung verwendet. |
|
Mehrfache Einbettung |
Für jeden Ankerpunkt wird eine Einbettung erzeugt. |
|
Standard-Einbettung |
Die Einbettung ordnet alle Ankerpunkte in einer Liste an |
Symbol: ![]()
Name des
XML-Elements: EmbeddingCreate
Schnittstelle: ModelEmbeddingIF
Kontext:
- Schritt
5.6.7 Ziel anlegen und pflegen
Wenn
kein Modellelement im Ziel gefunden wurde, weder über die Suche nach einer
Verbindung, noch über die Suche nach einem Ziel, so wird ein Modellelement
angelegt. Wenn ein, oder mehrere Modellelemente gefunden wurden, so werden
diese gepflegt.
Dieser Modellmorphismus legt
ein Modellelement im Zielmodell für jedes Modellelement im Quellmodell an, für
das kein Ziel gefunden wurde. Desweiteren werden an bestehenden und neu
angelegten Modellelementen Eigenschaften gesetzt. Dies erfolgt durch
untergeordnete Gruppen von Eigenschaftszuweisungen. Die Einbettung fürs Anlegen
wird beim Anlegen verwendet, um zu bestimmen wie das neu angelegte Modellelement
im Zielmodell mit anderen Modellelementen verknüpft ist. Wenn keine Einbettung
fürs Anlegen definiert ist, wird stattdessen die Einbettung für die Suche
verwendet.
Es stehen elf Klassen zur
Verfügung.
|
Klasse |
Verhalten |
|
Absolute Positionen in relative Positionen konvertieren |
Die absoluten Positionen von Innovator classiX werden in relative Positionen von Innovator X konvertiert. |
|
Führe Zuweisung durch |
Dem ersten Ankerpunkt wird der zweite Ankerpunkt zugewiesen |
|
Lege Modellelement an |
Lege Modellelement an. Der Parameter "createTemplate" bestimmt die Anlegeschablone. Der Parameter "stereotypeName" bestimmt den Stereotyp. Die erste Anlegeschablone, für die der Benutzer eine Ausführungsberechtigung hat, wird verwendet. Wenn weder der Parameter "createTemplate", noch der Parameter "stereotypeName" gefüllt sind, so wird nichts angelegt. Die Eigenschaften werden immer zugewiesen. Als Einbettung wird mindestens ein Ankerpunkt erwartet, der der Besitzer ist, es können aber auch mehrere Ankerpunkte sein. |
|
Lege Datentypdefinition an |
Diese Produktion ist für das Anlegen und die Pflege von Datentypdefinitionen. Sie benötigen keine Eigenschaftszuweisung unterhalb dieser Produktion, da sie bereits den Masterdatentyp und den ersten und zweiten Parameter setzt. Der Parameter "typesystem" bestimmt den Namen des Typsystems, das für die Datentypdefinition verwendet werden soll. |
|
Lege Diagramminhalt an |
Lege Diagramminhalt an. Es werden zwei Ankerpunkte benötigt: Das Diagramm und das logische Element zum Diagramminhalt. |
|
Diagramm rotieren |
Rotiert die Diagrammelemente des Diagramms. Das Diagramm ist der erste Ankerpunkt. |
|
Pfadsequenz erzeugen |
Die Produktion erzeugt auf dem Ankerpunkt eine im Parameter "pathSequence" angegebene Pfadstruktur. Die zu erzeugenden Elemente werden spezifiziert durch den Parameter "stereotypeName" bzw. "templateName". |
|
Pflege Sortierung |
Die Pflege der Sortierung kann über die beiden Parameter "sortType" und "unhandledSortPolicy" beeinflusst werden. Als Einbettung wird eine Liste von Ankerpunkten erwartet. Das erste Element der Liste muß der Besitzer der sortierten Elemente sein. Der Rest der List sind die zu sortierenden Elemente. |
|
Knotenpositionen ausstrecken |
Knotenpositionen ausstrecken |
|
Fehler ausgeben |
Wenn kein Modellelement im Ziel gefunden wurde, wird ein Fehler ausgegeben und die Modelltransformation abgebrochen. Vorhandene Modellelemente können jedoch gepflegt werden. |
|
Nichts anzulegen |
Wenn kein Modellelement im Ziel gefunden wurde, wird kein Modellelement angelegt. Vorhandene Modellelemente können jedoch gepflegt werden. |
Symbol: ![]()
Name des XML-Elements: CreateTarget
Schnittstelle: PatternProductionIF
Kontext:
- Schritt
5.6.8 Verbindung anlegen und pflegen
Eine
Verbindung zwischen den Modellelementen in der Quelle und im Ziel wird
angelegt. Die Verbindung wird nur angelegt, wenn keine Verbindung gefunden
wurde.
Der Modellmorphismus legt Verbindungen an zwischen dem Modellelement im Quellmodell und dem Modellelement im Zielmodell. Diese persistenten Kleber sind im Quellmodell oder im Zielmodell oder in beiden gespeichert. Es ist aber auch eine Implementierung denkbar, die den Kleber in einem dritten Modell, dem sogenannten Relationenmodell speichert.
Es gibt 4 Klassen, die alle ein anderes Verhalten implementieren.
|
Klasse |
Verhalten |
|
Abhängigkeit im Innovator |
Innerhalb eines Innovatormodells wird das Ziel über eine Abhängigkeit gesucht. |
|
Innovator zu externem Modell durch Proxy |
Von Innovator in ein anderes Modell wird per Proxy gesucht. |
|
Innovator zu Innovator durch Proxy |
Innerhalb des Innovatormodells wird nach Proxys gesucht. |
|
Keine persistente Verbindung |
Es erfolgt keine Suche über Verbindung. |
Symbol: ![]()
Name des
XML-Elements: CreateGlue
Schnittstelle: MappingModelGlueIF
Kontext:
- Schritt
5.7 Gruppen
Es gibt Aufgaben, die mit einer oder mehreren Gruppen erweitert werden können. Diese bündeln die Konfigurationselemente hauptsächlich mit dem Ziel, dass sie für den Benutzer übersichtlich sind. Eine eventuell zusätzliche Logik ist bei den einzelnen Gruppen erläutert.
5.7.1 Gruppe von Erweiterungen
Eine Gruppe von Erweiterungen
enthält Anweisungen, die Modellelemente zwischen den Speichern kopieren oder
verschieben oder aus einem Speicher entfernen und Anweisungen, die aus den Modellelementen
des Hauptspeichers eine Teilmenge auswählen oder von den Modellelementen im
Hauptspeicher zu anderen Modellelementen navigieren. Ein Beispiel einer Gruppe
ist
· Load from initial selection
Die Modellelemente der initialen Auswahl werden in den Hauptspeicher geladen.
· Process Objects("ownerTransitive")
Zu jedem Element werden alle transitiven Besitzer berechnet und die
Menge aller transitiven Besitzer ersetzt den bisherigen Inhalt des
Hauptspeichers.
· Process Property("type")=”Package”
Für jedes Element im Hauptspeicher wird geprüft, ob der Elementtyp
"Package" ist, und wenn nicht, wird es aus dem Hauptspeicher
entfernt.
· Save to active selection
Die übrig gebliebenen Modellelemente werden zur aktiven Auswahl hinzugefügt.
Insgesamt werden also die
besitzenden Pakete der ausgewählten Elemente
zur aktiven Auswahl hinzugefügt.
Die einzige Klasse, die für die Schnittstelle registriert ist, ist "Gruppe von Erweiterungen".
Symbol: ![]()
Name des XML-Elements: ExtensionGroup
Schnittstelle: ExtensionGroup
Kontext:
5.7.2 Gruppe von Ankerpunkten
Die Gruppe liefert die
Ankerpunkte die unterhalb der Gruppe definiert sind. Eine eventuell vorhandene Bedingung
filtert die gültigen Ankerpunkte.
Es stehen drei Klassen zur
Verfügung
|
Klasse |
Verhalten |
|
Gruppe von allen Ankerpunkten |
Alle Ankerpunkte dieser Gruppe müssen existieren, damit diese für die Einbettung verwendet werden. |
|
Gruppe von exklusiv alternativen Ankerpunkten |
Der erste gültige Ankerpunkt dieser Gruppe wird verwendet. |
|
Gruppe von möglichen Ankerpunkten |
Alle Ankerpunkte dieser Gruppe werden für die Einbettung verwendet. |
Symbol: ![]()
Name des XML-Elements: AnchorGroup
Schnittstelle: AnchorGroupIF
Kontext:
· Einbettung der Suche
· Einbettung fürs Anlegen
5.7.3 Gruppe von Eigenschaftszuweisungen
Die Eigenschaftszuweisungen in einer Gruppe werden nur ausgeführt, wenn eine eventuell vorhandene Bedingung zutrifft. Die Eigenschaftszuweisungen anderer Gruppen sind davon nicht betroffen. Die einzige Klasse, die für die Schnittstelle registriert ist, ist "Gruppe von Eigenschaftszuweisungen".
Symbol: ![]()
Name des
XML-Elements: UpdateGroup
Schnittstelle: FunctionalVariationPointGroup
Kontext:
- Ziel anlegen und pflegen
- Verbindung anlegen und pflegen
5.8 Weitere Konfigurationselemente
Unterhalb von Gruppen befinden sich noch weitere Konfigurationselemente, die im Folgenden aufgeführt sind. Unterhalb von diesen befinden sich keine weiteren Konfigurationselemente.
5.8.1 Laden
Kopiere alle Elemente in den Hauptspeicher. Der Hauptspeicher wird zuvor geleert. Die einzige Klasse, die für die Schnittstelle registriert ist, ist "Mengenoperation".
Symbol: ![]()
Name des
XML-Elements: Load
Schnittstelle: SetExtensionStatementIF
Kontext:
·
Gruppe von Erweiterungen
5.8.2 Speichern
Fügt den Inhalt des Haupspeichers zum angegebenen Speicher
hinzu. Wenn der angegebene Speicher ein Zwischenspeicher ist, wird der Inhalt des
Hauptspeichers nicht hinzugefügt sondern überschreibt den Inhalt des
Zwischenspeichers. Die einzige Klasse, die für die Schnittstelle registriert
ist, ist "Mengenoperation".
Symbol: ![]()
Name des XML-Elements: Save
Schnittstelle: SetExtensionStatementIF
Kontext:
·
Gruppe von Erweiterungen
5.8.3 Vereinigen
Lädt den Inhalt des angegebenen Speichers in den Hauptspeicher und vereinigt diesen mit dem bisherigen Inhalt. Die einzige Klasse, die für die Schnittstelle registriert ist, ist "Mengenoperation".
Symbol:
![]()
Name des XML-Elements: Union
Schnittstelle: SetExtensionStatementIF
Kontext:
·
Gruppe von Erweiterungen
5.8.4 Schneiden
Lädt den Inhalt des angegebenen Speichers in den Hauptspeicher und schneidet diesen mit dem bisherigen Inhalt. Die einzige Klasse, die für die Schnittstelle registriert ist, ist "Mengenoperation".
Symbol:
![]()
Name des XML-Elements: Intersect
Schnittstelle: SetExtensionStatementIF
Kontext:
·
Gruppe von Erweiterungen
5.8.5 Abziehen
Lädt den Inhalt des angegebenen Speichers in den Hauptspeicher und zieht ihn vom bisherigen Inhalt ab. Die einzige Klasse, die für die Schnittstelle registriert ist, ist "Mengenoperation".
Symbol: ![]()
Name des
XML-Elements: Subtract
Schnittstelle: SetExtensionStatementIF
Kontext:
·
Gruppe von Erweiterungen
5.8.6 Bearbeiten
Filtert die Modellelemente des Hauptspeichers mit einer Bedingung oder berechnet zu jedem Modellelement im Hauptspeicher ein oder mehrere referenzierte Modellelemente. Das Berechnungsergebnis überschreibt den Hauptspeicher. Die einzige Klasse, die für die Schnittstelle registriert ist, ist "Einfache Erweiterung".
Symbol: ![]()
Name des
XML-Elements: Process
Schnittstelle: FilterExtensionStatementIF
Kontext:
- Gruppe von Erweiterungen
5.8.7 Logische Verknüpfung
Die enthaltenen Bedingungen und logischen Verknüpfungen
werden verknüpft. Die Art der logischen Verknüpfung wird durch die Klasse
realisiert. Es stehen fünf Klassen zur Verfügung
|
Klasse |
Verhalten |
|
ENTWEDER ODER |
Die ENTWEDER ODER Verknüpfung verknüpft die enthaltenen Einträge und liefert WAHR, wenn eine ungerade Anzahl der Einträge WAHR liefern. |
|
NICHT UND |
Die NICHT UND Verknüpfung verknüpft die enthaltenen Einträge und liefert WAHR, wenn alle FALSCH liefern. |
|
NICHT ODER |
Die NICHT ODER Verknüpfung verknüpft die enthaltenen Einträge und liefert WAHR, wenn einer FALSCH liefert. |
|
UND |
Die UND Verknüpfung verknüpft die enthaltenen Einträge und liefert WAHR, wenn alle WAHR liefern. |
|
ODER |
Die ODER Verknüpfung verknüpft die enthaltenen Einträge und liefert WAHR, wenn einer WAHR liefert. |
Symbol: ![]()
Name des XML-Elements: Operator
Schnittstelle: OperatorIF
Kontext:
- Quelle bestimmen
- Verbindung suchen
- Ziel suchen
- Gruppe von Eigenschaftszuweisungen
- Logische Verknüpfungen
- Gruppe von Ankerpunkten
- Konflikt
5.8.8 Bedingung
Die Bedingung evaluiert auf WAHR oder FALSCH. Die zur Verfügung stehenden fünf Klassen sind.
|
Klasse |
Verhalten |
|
Datentypdefinition wurde abgebildet |
Datentypdefinition wurde abgebildet |
|
Bedingung |
Die Bedingung enthält im Parameter "expression" einen Ausdruck, der zur Laufzeit ausgewertet wird. Mehr im Kapitel Einfache Ausdrücke. |
|
Entität ist Primärentität |
Entität ist Primärentität |
|
Ist bereits mit anderen Modellelement in der Quelle verbunden |
Ist bereits mit anderen Modellelement in der Quelle verbunden |
|
Tabelle wurde denormalisiert |
Die Art der Denormalisierung steht im Parameter "denormalizationKind". Die Funktion ist dann wahr, wenn die korrespondierende Tabelle die gleiche Art der Denormalisierung hat wie im Parameter gesetzt. |
Symbol: ![]()
Name des
XML-Elements: Condition
Schnittstelle: ConditionIF
Kontext:
- Quelle bestimmen
- Verbindung suchen
- Ziel suchen
- Gruppe von Eigenschaftszuweisungen
- Logische Verknüpfung
- Gruppe von Ankerpunkten
- Konflikt
5.8.9 Einschränkung
Die Einschränkung evaluiert auf WAHR oder FALSCH. Der Unterschied zur Bedingung ist, dass ein mit einer unzutreffenden Einschränkung versehener Kontext nicht ausgeführt wird, während ein mit einer unzutreffenden Bedingung versehener Kontext ausgeführt wird, aber die Bedingung bei der Ausführung beachtet. Die einzige zur Verfügung stehende Klasse ist.
|
Klasse |
Verhalten |
|
Einschränkung |
Die Einschränkung enthält im Parameter "expression" einen Ausdruck, der zur Laufzeit ausgewertet wird. Mehr im Kapitel Einfache Ausdrücke. |
Symbol: ![]()
Name des XML-Elements: Constraint
Schnittstelle: ConstraintIF
Kontext:
- Quelle bestimmen
- Verbindung suchen
- Ziel suchen
- Gruppe von Eigenschaftszuweisungen
- Logische Verknüpfung
- Gruppe
von Ankerpunkten
- Konflikt
5.8.10 Ankerpunkt
Ein Ankerpunkt ist ein einzelnes Modellelement im
Zielmodell, das zusammen mit den anderen Ankerpunkten die Einbettung für das zu
suchende, oder anzulegende Modellelement beschreibt. Es stehen acht Klassen zur Verfügung
|
Klasse |
Verhalten |
|
Ankerpunkt |
Ein Ankerpunkt ist ein Aufhänger für ein Modellelement im Ziel. Dabei beschreibt der Typ die Rolle der Aufhängers bezüglich des Zielelements. Der Parameter "mode" beschreibt die Rolle noch genauer. Der Parameter "step" beschreibt, in welchem Modelltransformationsschritt der Aufhänger abgebildet wurde. |
|
Ankerpunkt für Innovator |
Ankerpunkt für Innovator unterstützen zusätzliche Rollen, siehe Parameter "mode". Außerdem können Sie, bevor die Rolle mit dem Parameter "mode" bestimmt wird, mit dem Parameter "preNavMode" eine weitere Navigation vornehmen. |
|
Ankerpunkt für Innovator für Navigation |
Ankerpunkt für Innovator für Navigation. Im Parameter "preNavExpression" können Sie einen Ausdruck angeben, der im Quellmodell navigiert, bevor der Ankerpunkt bestimmt wird. |
|
Ankerpunkt für Navigation |
Ankerpunkt für Navigation. Im Parameter "preNavExpression" können Sie einen Ausdruck angeben, der im Quellmodell navigiert, bevor der Ankerpunkt bestimmt wird. |
|
Ankerpunkt für abhängige Schritte |
Ein Ankerpunkt ausschließlich für die Verwendung in abhängigen Schritten. Er liefert das Zielelement des übergeordneten Schrittes. Mit dem Parameter "step" muß der übergeordnete Schritt bei mehreren Schritten eindeutig angegeben werden. |
|
Ankerpunkt für gerichtete Innovator-Beziehungen |
Ankerpunkt für gerichtete Beziehungen im Innovator. Es kann auf Quell als auch auf Zielseite der Beziehung navigiert werden. Der Ankerpunkt benötigt eine gerichtete Beziehung als Quellelement. |
|
Ankerpunkt für ungerichtete Innovator-Beziehungen |
Ankerpunkt für ungerichtete Innovator Beziehungen. Es wird auf die Typen der Endpunkte der Beziehung navigiert. |
|
Ankerpunkt für ungerichtete Innovator-Beziehungsenden |
Ankerpunkt für ungerichtete Innovator Beziehungsenden. Es wird auf die Endpunkte der Beziehung navigiert. |
Symbol: ![]()
Name des XML-Elements: Anchor
Schnittstelle: ModelAnchorIF
Kontext:
- Gruppe von Ankerpunkten
- Konflikt
5.8.11 Konflikt
Ein Konflikt kann innerhalb einer Gruppe von Eigenschaftszuweisungen definiert werden, oder innerhalb der Ankerpunkte. Der angegebene Konflikt wird geprüft, bevor eine Übertragung aus der Gruppe ausgeführt wird. Wenn der Konflikt besteht, werden die Eigenschaften nicht zugewiesen.
Stattdessen kann der Konflikt aufgelöst werden. Dies kann automatisch erfolgen, oder der Benutzer wählt aus mehreren Lösungen. Ebenso wird der Konflikt überprüft, bevor ein Ankerpunkt verwendet wird. In diesem Fall wird bei Auftreten des Konfliktes, der Ankerpunkt nicht verwendet. Stattdessen kann der Benutzer einen Ankerpunkt wählen, oder es wird automatisch einer ausgewählt. Die einzige Klasse, die für die Schnittstelle registriert ist, ist "Konflikt".
Symbol: ![]()
Name des XML-Elements: Conflict
Schnittstelle: ConflictType
Kontext:
- Gruppe von Eigenschaftszuweisungen
- Ankerpunkt
5.8.12 Anlegen
Eigenschaftszuweisung. Setzt die angegebene Eigenschaft an
einem neu angelegten Zielelement auf den angegebenen Wert, der eventuell aus
der Eigenschaft des Quellmodells berechnet wird. Bei einem existierenden
Modellelement wird nichts geändert. Es stehen
drei Klassen zur Verfügung
|
Klasse |
Verhalten |
|
Einfache Übertragung |
Die einfache Übertragung setzt anhand des Ausdrucks im Parameter "expression" eine Eigenschaft des Modellelements im Ziel. |
|
Keine Änderung |
Keine Änderung |
|
Zu Speicher hinzufügen |
Diese Übertragung speichert das Modellelement im Zielmodell in einem Speicher. Der Speicher wird über den Parameter "store" festgelegt. |
Symbol: ![]()
Name des XML-Elements: Create
Schnittstelle: FunctionalVariationPointIF
Kontext:
- Gruppe von Eigenschaftszuweisungen
- Konflikt
5.8.13 Ändern
Eigenschaftszuweisung. Ändert die angegebene Eigenschaft am existierenden oder neu angelegten Zielelement und setzt den angegebenen Wert, der eventuell aus der Eigenschaft des Quellmodells berechnet wird. Es stehen diesselben Klassen zur Verfügung wie bei Anlegen.
Symbol: ![]()
Name des XML-Elements: Update
Schnittstelle: FunctionalVariationPointIF
Kontext:
- Gruppe von Eigenschaftszuweisungen
- Konflikt
5.9 Referenz
Eine Referenz zeigt auf eine andere Aufgabe, Gruppe oder weitere Konfigurationselemente, aber nicht auf eine andere Referenz oder auf einen Schritt.
Das referenzierte Konfigurationselement wird an der Stelle der Referenz ausgeführt, so als ob eine Kopie von ihr an dieser Stelle stünde. Dies erleichtert das nachträgliche Bearbeiten einer Konfiguration, weil nur an einer Stelle, nämlich am referenzuerten Konfigurationselement Änderungen durchgeführt werden müssen. Die einzige Klasse, die für die Schnittstelle registriert ist, ist "Referenz".
Symbol: ![]()
Name des XML-Elements: Reference
Schnittstelle: ReferenceIF
Kontext:
· Schritt
· Aufgabe
· Gruppe
6.1 Zugriff auf Optionen
Um eine Option zu lesen, müssen Sie sie zuvor setzen. Jeder Schreibzugriff auf eine Option überschreibt den vorherigen Wert. Sie können den Wert auf mehrere Arten setzen:
- In der Optionsdatei (über die Konfigurationsoberfläche). Diese wird am Anfang der Modelltransformation geladen.
- Als Argument der Engineering-Aktion (über die Konfigruation der Aktionssequenz). Dieses überschreibt eventuell vorhandene Werte aus der Optionsdatei.
- In der Registerklasse (als SDK-Entwickler).
- In der Ablaufsteuerung (über die Konfigurationsoberfläche). Die Option wird erst während des Ablaufs gesetzt.
- In der Ablaufsteuerung aus einer temporären Datei (über die Konfigurationsoberfläche). So kann zum Beispiel eine Option wieder auf den Wert gesetzt werden, den sie vor einer Änderung hatte.
- Im Optionsdialog kann der Benutzer Optionswerte setzen. Der M2M-Konfigurator muss dies in der Ablaufsteuerung konfigurieren.
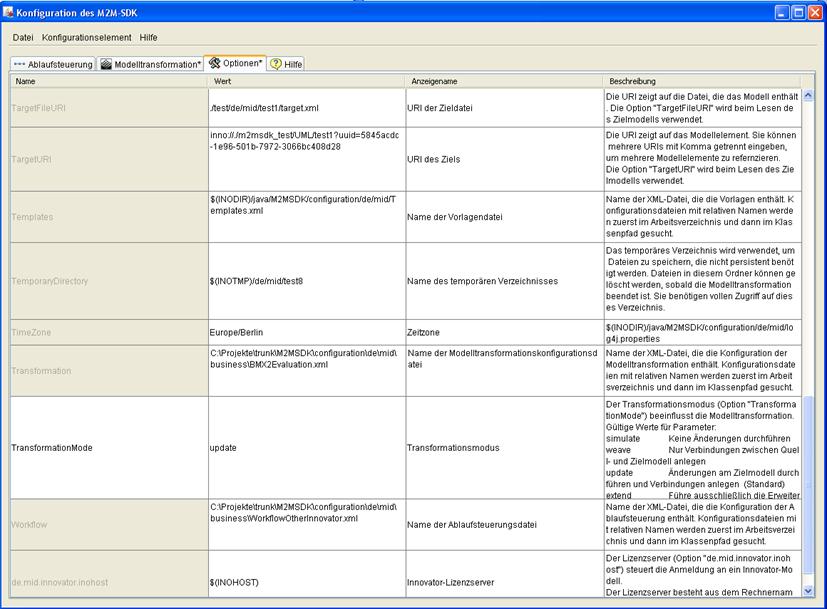
Abbildung 3:Konfigurationsoberfläche (aktiver Reiter: Optionen)
Sie können beliebige Werte als Optionswerte verwenden und Sie können auch Umgebungsvariablen verwenden. Benutzen Sie dazu einfach die Syntax $(<Variablenname>).
Die Optionen können an mehreren Stellen gelesen werden:
- Ihre eigenen Client-Anwendungen, Server-Anwendungen und Dialoge können die Optionswerte bei der Ausführung auswerten.
- Eine Option kann in der Modelltransformation geprüft werden. Dazu fügen Sie die Prüfung der Option am Konfigurationselement in der Modelltransformationskonfiguration hinzu. Das Konfigurationselement wird dann ausgeführt, wenn alle Optionen den angegebenen Wert haben.
- In der Ablaufsteuerung können Sie die Optionen in einer temporären Datei speichern. Weil das temporäre Verzeichnis pro Benutzer und Rechner verschieden sein kann, können Sie so benutzer- und rehnerspezifische Optionswerte erreichen.
- Der Benutzer kann die Optionen im Optionsdialog sehen. Der M2M-Konfigurator muss dies in der Ablaufsteuerung konfigurieren.
Sie können die Verwendungsstellen einer Option in der Ablaufsteuerung und in der Modelltransformation in der Konfigurationsoberfläche finden.
6.2 Verfügbare Optionen
Verschiedene Optionen sind bereits verfügbar, die das Verhalten von Client-Anwendungen, Server-Anwendungen und Dialogen beeinflussen. Manche steuern auch die Ablaufsteuerung. Hier ist eine Liste der verfügbaren Optionen:
· ChangeSummary ist die Grenze für die Anzahl an Änderungen, ab der nur noch eine Zusammenfassung ausgegeben wird und keine Details der Änderungen.
· Customer ist der Pfad und Name der Datei der Kundenanpassung. Beachten Sie den Hinweis zur Dateiverwaltung.
· CustomerMode schaltet die Verwendung einer Kundenanpassung ein
· DebugMode schaltet die Fehlersuche ein oder aus.
· INODIR ist das INODIR-Verzeichnis der Innovator-Installation.
· INOHOST ist der Lizenzserver. Er wird als Rechnername und Portnummer angegeben getrennt mit Doppelpunkt angegeben.
· LogLevel beeinflusst das Protokoll und Nur Nachrichten der angegebenen Fehlerebene oder höher werden protokolliert.Gültige Werte sind: Fatal, Error, Warning, Change, Info, Debug und Trace.
· MappingId ist der Name der Mappingkonfiguration das die Proxies besitzt.
· Option ist der Pfad und Name der Datei der Optionen. Beim Laden des Optionsmodells werden die Optionen aus dieser Datei ebenfalls geladen. Ebenso wird die darin referenzierte Optionsdatei importiert usw. Beachten Sie den Hinweis zur Dateiverwaltung.
· RMIPolicy ist der Pfad und Name der Datei der Sicherheitsrichtlinien. Beachten Sie die Notiz zur Dateiverwaltung. Die Datei wird beim verteilten Rechnen benötigt.
· RMIServer bestimmt, welcher Prozess für die Serveranwendungen verwendet wird. Wenn kein RMI server definiert ist, laufen die Serveranwendungen im gleichen Prozess wie die Clientanwendungen. Lesen Sie mehr zum verteilten Rechnen im Kapitel 12. Verteilte Berechnung. Gültige Werte haben folgendes Schema <Rechnername>:[<Portnummer der Fabrik>[-<maximale Portnummer>]]. Wenn Sie den Port weglassen, wird 1099 angenommen. Wenn Sie die maximale Portnummer weglassen, wird die Portnummer der Fabrik +100 angenommen.
· RegisterClass ist der qualifizierte Klassenname der Klasse, die die anderen Klassen registriert und die Optionen mit Standardwerten versorgt.
· ShowDialog zeigt alle Dialoge an oder verbirgt sie.
· SourceFileURI zeigt auf die Datei, die das Modell beinhaltet. Die Option wird von der Client-Anwendung "Lies Quellelemente aus" gelesen.
· SourceURI zeigt auf ein oder mehrere Modellelemente. Mehrere URIs werden mit Kommata getrennt. Die Option wird von der Client-Anwendung "Lies Quellelemente aus" gelesen.
· StartFolder ist der absolute Pfad des Startverzeichnisses für den Dateiauswahldialog.
· TargetFileURI zeigt auf die Datei, die das Modell beinhaltet. Die Option wird von der Client-Anwendung "Lies Zielelemente aus" gelesen.
· TargetURI zeigt auf ein oder mehrere Modellelemente. Mehrere URIs werden mit Kommata getrennt. Die Option wird von der Client-Anwendung "Lies Zielelemente aus" gelesen.
· Templates ist der Pfad und Name der Datei der Vorlagen. Beachten Sie den Hinweis zur Dateiverwaltung.
· TemporaryDirectory ist der absolute Pfad des temporären Verzeichnisses.
· TimeZone beeinflusst das Datum und die Uhrzeit der Nachrichten im Protokoll.
· Transformation ist der Pfad und Name der Datei der Modelltransformationskonfiguration. Beachten Sie den Hinweis zur Dateiverwaltung.
·
TransformationMode beeinflusst die Modelltransformation.
Gültige Werte für Parameter:
simulate Keine Änderungen durchführen
interconnect Nur
Verbindungen zwischen Quell- und Zielmodell anlegen
update Änderungen am Zielmodell durchführen
und Verbindungen anlegen
extend Führe ausschließlich die Erweiterung
der Auswahl durch
· Workflow ist der Pfad und Name der Datei der Ablaufsteuerung. Beachten Sie den Hinweis zur Dateiverwaltung.
Die Dateien sollten eine absoluten Pfad oder einen Pfad relativ zum Arbeitsverzeichnis oder zum Klassenpfad haben. Dateien mit relativenm Pfad werden zuerst im Arbeitsverzeichnis und dann im Klassenpfad gesucht. Wenn die Datei nicht gefunden wird, wird die entsprechende Standarddatei aus dem Verzeichnis $(INODIR)/java/M2MSDK/configuration/de/mid stattdessen verwendet. Wenn eine Datei nicht schreibbar ist, wird stattdessen eine Kopie ins temporäre Verzeichnis gelegt.
6.3 Ihre eigenen Optionen
Der M2M-Konfigurator kann eigene Optionen in der Konfigurationsoberfläche im Reiter "Optionen" anlegen. Der SDK-Entwickler kann eigene Optionen im der Erweiterung anlegen. Mehr finden Sie dazu im Kapitel 10.2_Eigene Optionen.
Die Kundenanpassung modifiziert und ergänzt eine vorhandene Ablaufsteuerung oder eine vorhandene Modelltransformation. Sie ist der einfachste und sicherste Weg, eine vorhandene Modelltransformation auf die Bedürfnisse eines Kunden anzupassen. Technisch ist eine Kundenanpassung in einer weiteren Datei gespeichert. Zur Laufzeit werden die Kundenanpassungen auf die Ablaufsteuerung und die Modelltransformation angewandt. Die Kundenanpassungen verweisen auf einzelne Konfigurationseinträge in der Konfiguration der Ablaufsteuerung und der Modelltransformation. Diese dürfen daher nicht gelöscht werden. Die Datei mit der Kundenanpassung wird automatisch angelegt und gepflegt, wenn der Benutzer in der Konfigurationsoberfläche des M2M-SDK mit Kundenanpassung verwendet (Option CustomerMode=true). Die Änderungen werden in diesem Fall nicht in die Konfigurationsdateien für Ablaufsteuerung oder Modelltransformation gespeichert, sondern in die der Kundenanpassung. Das Verschieben in der Modelltransformation oder Ablaufsteuerung ist dann nicht möglich, stattdessen wird kopiert. Das Löschen eines Konfigurationseintrags ist nicht möglich, stattdessen muss eer deaktiviert werden.
7.1 Definition einer Kundenanpassung
Die Kundenanpassung enthält alle Einfügungen und Änderungen an einer Modelltransformation und Ablaufsteuerung.
Symbol: ![]()
Name des XML-Elements: Customer
Schnittstelle: Customer
7.2 Änderungsaufgabe
In einer Änderungsaufgabe werden Einfügungen und Änderungen thematisch gruppiert. Sie dient dem Benutzer dafür einen Überblick über zusammenhängende Einfügungen und Änderungen zu behalten.
Symbol: ![]()
Name des XML-Elements: ChangeSet
Schnittstelle: ChangeSet
Kontext:
- Kundenanpassung
7.3 Einfügung
Eine Einfügung wird jedesmal erzeugt, wenn der Benutzer in der Konfigurationsoberfläche des M2M-SDK einen neuen Konfigurationseintrag anlegt. Die Einfügung enthält den eingefügten Konfigurationseintrag samt all dessen enthaltenen Konfigurationseinträgen. Außerdem enthält er Parameter, die beschreiben, wo die Einfügung vorgenommen wurde.
Symbol: ![]()
Name des XML-Elements: Insert
Schnittstelle: Insert
Kontext:
- Kundenanpassung
- Änderungsaufgabe
7.4 Änderung
Eine Änderung wird jedesmal erzeugt, wenn der Benutzer in der Konfigurationsoberfläche des M2M-SDK einen vorhandenen Konfigurationseintrag ändert. Die Änderung enthält den geänderten Konfigurationseintrag. Außerdem enthält er Parameter, die beschreiben, welcher Konfigurationseintrag geändert wurde.
Symbol: ![]()
Name des XML-Elements: Modification
Schnittstelle: Modification
Kontext:
- Kundenanpassung
- Änderungsaufgabe
8. Parameter
Parameter sind ein wichtiger Teil der Konfiguration. Die Parameter werden immer an den Konfigurationseinträgen eingetragen und wirken auf die implementierende Klasse des Konfigurationseintrags. Die an einem Konfigurationseintrag unterstützten Parameter werden durch die Klasse definiert. Die Bedeutung eines Parameters für die Ausführung ist in der Klasse definiert. Parameter bestehen aus einem konstanten Namen und einem Wert. Es ist über die Modelltransformationskonfiguration nicht möglich, die Namen von Parametern zu ändern oder neue Parameter außer den von der Klasse unterstützten anzulegen. Solch eine Erweiterung muss vom SDK-Entwickler vorgenommen werden. Parameter müssen nicht registriert werden, sondern nur von der überschriebenen Methode ConfigurableItem::getKnownParameters zurückgeliefert werden.
Als Wert eines Parameters können boolesche Werte, Zeichenketten, Referenzen auf Konfigurationseinträge, Aufzählungswerte sein. Sie können Konstanten sein oder durch einfache Ausdrücke definiert werden.
Ein Beispiel für einen Parameter ist sourceMetaModel an der Klasse ModelTransformation, die das Metamodell des Quellmodells angibt. Ein anderes Beispiel ist der Parameter createTemplate an der Klasse PatternProductionBaseInnovator, der die Anlegeschablone festlegt, die in dieser Aufgabe zum Anlegen eines Modellelements im Innovator verwendet wird. Es gibt auch Parameter, bei denen es Sinn macht, keine Konstante, sondern einen einfachen Ausdruck anzugeben. Wenn zum Beispiel an der Klasse PatternTargetMatchInnovator der Parameter name den Wert Property("name") hat, erfolgt die Suche nach Modellelementen, die denselben Namen haben, wie das jeweilige Quellelement.
Die Anweisungen bei der Erweiterung des Quellmodells und die Einschränkungen bei der Suche und die Eigenschaftszuweisungen beim Anlegen und Pflegen sind Funktionen. Diese Funktionen werden definiert durch eine Klasse und einem Ausdruck. Die Klasse der Funktion implementiert die Schnittstelle FilterExtensionStatementIF, BooleanFunction oder FunctionalVariationPointIF. Die Klasse interpretiert den Ausdruck und holt vom Modellelement den Wert der entsprechenden Eigenschaft oder setzt den Wert der Eigenschaft. Sie können eigene Funktionen schreiben, indem Sie diese Schnittstellen implementieren.
Eine Funktion kann für manche Parameter verwendet werden oder im Wert von
·
Ändern
·
Anlegen
9.1 Einfache Ausdrücke
Im Parameter expression der Klassen SimpleCondition, SimpleExtension und SimpleTransform können Sie einen Einfachen Ausdruck angeben. Einfache Ausdrücke sind Ausdrücke, mit denen Sie auf Eigenschaften von Modellelementen zugreifen können und auch Berechnungen auf Listen und Werten anstellen können. Einfach sind sie deswegen, weil Sie so ohne zusätzlichen Quelltext lediglich durch die Definition eines Ausdrucks in der Konfigurationsoberfläche komplexe Abfragen durchführen können. Die Ausdrücke selbst können und sollen also durchaus mächtig und komplex sein, sie sollen lediglich Ihre Arbeit einfach machen. Die vereinfachte Syntax in Backus-Naur-Form ist
<Terms> ::= < Property >'='< Property >
<Property>
::= <ConstantProperty> | <ListProperty> | <CompositeProperty>
<ConstantProperty>
::= '"'<Word>'"'
<Word>
::= |<DigitOrLetter> <Word>
<DigitOrLetter>
::= A|B|C|...|Z|a|b|c|...|z|0|1|2|...|9
<ListProperty>
::= <PropertyType>'('<Arguments>')'
<Arguments>
::= | <Property> | <Arguments>','<Property>
<CompositeProperty>
::= <Property>'.'<Property>
Die Eigenschaft <Terms> ist abhängig vom Kontext ein Vergleich
oder eine Zuweisung. Dabei ist je nach Verwendungsstelle das Modellelement im
Quellmodell oder im Zielmodell betroffen. Bei Konfigurationseinträgen unterhalb
der Aufgaben Erweiterung des Quellmodells und Quelle einschränken ist das Quellmodell
betroffen. Bei Konfigurationseinträgen unterhalb der Aufgaben Verbindung suchen, Ziel suchen, Ziel anlegen
und pflegen und Verbindung
anlegen und pflegen ist auf der rechten Seite
des Terms das Quellmodell und auf der linken Seite des Ausdrucks das Zielmodell
betroffen. An einem Konfigurationseintrag des Typs Bearbeiten,
Und, Oder, Und
Nicht und Oder Nicht ist der Term ein Vergleich.
An einem Konfigurationseintrag des Typs Ändern und Anlegen ist der Term eine Zuweisung. Es muss immer ein
Term verwendet werden. Eine Ausnahme ist der Konfigurationseintrag des Typs Bearbeiten. Dort kann auch direkt eine Eigenschaft
<Property> verwendet werden, die dann als Navigation zu einem anderen
Modellelement ausgewertet wird.
Eine Konstante <ConstantProperty> ist eine Zeichenkette oder eine Zahl, zum Beispiel "name".
Eine Eigenschaft mit untergeordneten Eigenschaften <ListProperty> wird evaluiert, indem zuerst die untergeordneten Eigenschaften evaluiert werden und dann die Eigenschaft selbst. Zum Beispiel
Property("name")
liefert den Namen des Modellelements.
StringConcat("Prefix", Property("name"), "Postfix") liefert den Namen des Modellelements mit einem Präfix und einem Postfix.
StringUpper(Property("name")) liefert den Namen des Modellelements in Großbuchstaben.
Collect(Object("owned"), Property("name")) liefert die Namen der enthaltenen Modellelemente.
Collect(Select(Object("owned"), Equals(Property("type"), "CLClass")), Property("name")) liefert die Namen der enthaltenen Modellelemente, deren Elementyp "CLClass" ist.
Eine zusammengesetzte Eigenschaft <CompositeProperty> wendet die zweite Eigenschaft auf das Ergebnis der ersten Eigenschaft an. Zum Beispiel
Object("owner").Property("name") liefert den Namen des Besitzers.
Beachten Sie den Unterschied zu Collect(Objects("owned"), Property("name")) ist zulässig, nicht jedoch Objects("owned").Property("name"), weil hier Property("name") nicht auf das Ergebnis von Objects("owned") angewendet werden kann, weil das eine Liste ist. Object("owner") liefert dagegen nur ein einzelnes Modellelement, daher kann die zusammengesetzte Eigenschaft evaluiert werden.
Es gibt eine große Anzahl an Eigenschaften, die Ihnen zum Zugriff auf die Modellelemente zur Verfügung stehen. Viele arbeiten aber nicht auf Modellelementen, sondern auf logischen Werten, Zahlen, Zeichenketten oder Listen. Der Typ der Eigenschaft gibt vor, welche Art von Information beschafft wird. Die Argumente legen weiteres fest. Mehr Informationen zu den Eigenschaften finden Sie in den Tooltips in der Konfigurationsoberfläche.
Eigenschaften auf logischen Werten
- And
- Not
- NotAnd
- NotOr
- Or
- Xor
Eigenschaften auf Zahlen
- Avg
- Diff
- Div
- Max
- Min
- Mod
- Mul
- Sum
Eigenschaften auf Listen
- Collect liefert zu einer Liste eine Liste der Werte.
- Exists prüft, ob ein Modellelement einer Liste eine angegebene
Bedingung
erfüllt. - ListContains prüft,
ob der zweite Parameter im ersten enthalten ist oder gleich ist
- ListIndexOf liefert
das erste Vorkommen des zweiten Parameters im ersten
- ListSize liefert die Länge der Liste
- Intersect liefert die
Modellelemente, die in beiden Listen enthalten sind
- Reject liefert die Modellelemente einer Liste, die eine Bedingung nicht erfüllen.
- Reverse liefert die
Modellelemente einer Liste in umgekehrter Reihenfolge
- Select liefert die Modellelemente einer Liste, die eine Bedingung erfüllen.
- Subtract liefert die
Modellelemente, die in der ersten und nicht in der zweiten
enthalten sind - Union liefert die
Modellelemente, die in mindestens einer der beiden Listen enthalten sind
Eigenschaften auf Zeichenketten
- StringConcat liefert die aneinandergehängten Zeichenketten
- StringContains liefert WAHR, wenn die erste
Zeichenkette eine der folgenden enthält
- StringFirstNonEmpty
- StringFormat liefert eine Zeichenkette,
die anhand der ersten Zeichenkette formattiert
ist - StringIndexOf liefert die Position des
ersten Auftretens der zweiten Zeichenkette in der
ersten Zeichenkette - StringIsEmpty liefert WAHR, wenn die
Zeichenkette leer ist
- StringLength liefert die Länge einer
Zeichenkette
- StringLower liefert die in Kleinbuchstaben konvertierte Zeichenkette
- StringRegExp
- StringReplace
- StringStore
- StringSubString
- StringTrim
- StringUpper liefert die in Großbuchstaben konvertierte Zeichenkette
Eigenschaften auf Modellelementen
- Object liefert eine Referenz des Modellements.
- Objects navigiert zu mehreren Modellelementen.
- Property liefert ein Merkmal des Modellelements.
- StereotypeProperty liefert eine Stereotypeigenschaft des Modellelements
- FilterType
- FilterName
- IsElementMapped liefert WAHR, wenn das Modellelement
im angegebenen Schritt
abgebildet wurde - IsStereotypePropertyDefault
- IsTargetElementMapped
- MappedElement liefert das abgebildete Modellelement für den angegebenen Schritt
- Path
- zusätzlich für Innovator-Modelle:
- Label liefert den Wert eines Labels
- Text liefert den unformattierten Text eines Spezifikationstextes
- FlowText liefert den formattierten Text eines Spezifikationstextes
- Stereotype liefert Informationen über den
Stereotyp und die Anlegeschablone eines
Modellelements
Sonstige Eigenschaften
· Equals vergleicht zwei Ausdrücke und liefert wahr, wenn beide Ausdrücke gleich sind.
· Option liefert den aktuellen Wert der Option.
· StringKeyValuePair liefert die Zeichenkette "a=b" für zwei Argumente a und b. Es kann in einer StringMap verwendet werden.
· StringMap liefert eine Zeichenkette abhängig von der Auswertung eines Ausdrucks und einer Liste von Zeichenketten der Form "a=b".
10.1 Hilfe für den SDK-Entwickler
Um zu erfahren, welche Schnittstellen der SDK-Entwickler implementieren muss, reicht normalerweise ein Blick in dieses Referenzhandbuch in die Kapitel Erweiterbarkeit bzw. Modelltransformation. In der Konfigurationsoberfläche kann der SDK-Entwickler auch den zu ändernde Konfigurationseintrag auswählen und über das Menü die Hilfe aufrufen. So kann er in die entsprechende Stelle der API-Dokumentation springen.
Abbildung 4:Konfigurationsoberfläche (aktiver Reiter: Hilfe)
10.2 Information und Hilfe für den M2M-Konfigurator
Um zu erfahren, welches Verhalten von welcher Klasse implementiert wird, einfach mit der Maus eine gewisse Zeit über der Auswahlliste verweilen bis der Tooltip erscheint. Der Tooltip wird auch für Parameter und Parameterwerte angezeigt. Auch im Editor für einfache Ausdrücke zeigt der Tooltip Informationen über die Eigenschaften oder Syntaxfehler an. Viele Inhalte dieses Referenzhandbuchs sind als Tooltip kontextsensitiv in der Konfigurationsoberfläche hinterlegt. In der Hilfe finden Sie unter Overview>Description eine Auflistung aller Dokumente zum M2M-SDK, darunter Releaseinfos, Übungen und Anleitungen.
10.3 Information für den M2M-Transformer
Protokollereignisse werden auf die Konsole ausgegeben. Die Protokollinformation wird auch in die Protokolldatei ausgegeben. Desweiteren kann die Information auch in einem Dialog als Ablaufschritt dem Benutzer visualisiert werden (siehe Zeige Protokoll an). Während der Modelltransformation informiert eine Fortschrittsanzeige den Benutzer über den aktuellen Schritt und das bearbeitete Modellelement. Die Anzeige und die Vorschau der Änderungen (siehe Zeige Änderungen an) erfolgt ebenfalls anhand der Daten im Protokoll. Das Protokoll und das Fortschrittsmodell laufen im Server. Der Client wird also nicht aktiv aufgerufen, sondern ruft in regelmässigen zeitlichen Abständen Informationen aus den Modellen ab und zeigt diese dem Benutzer an bzw. schreibt diese auf die Konsole oder in eine Datei.
Mit der Option LogLevel geben Sie die Protokollebene an, ab der Nachrichten ins Protokollmodell gespeichert werden. Wenn die Nachrichten einer niedrigeren Protokollebene nicht ins Protokoll geschrieben werden, dann sind diese später auch nicht mehr zugänglich. Andererseits vermindert eine zu niedrige Protokollebene die Performance. Wenn Sie zum Beispiel die Protokollebene auf Warning setzen, werden keine Änderungsnachrichten mehr gespeichert und können daher auch nicht mehr angezeigt werden. Daher ist es sinnvoll, die Protokollebene mindestens auf Change zu lassen.
Mit der Systemeigenschaft java.util.logging.config.class können Sie festlegen, woher die Einstellungen zum Logging geladen werden. Mehr über Logging erfahren Sie unter http://docs.oracle.com/javase/7/docs/technotes/guides/logging/index.html. Standardmässig wird keine Klasse verwendet. Sie können die Klasse de.mid.innovator.util.Log verwenden, um die Protokollausgabe in Dateien im temporären Verzeichnis auszugeben.
11.1 Verhalten
Wenn Sie eine Erweiterung des M2M-SDKs schreiben wollen, müssen Sie eine Schnittstelle implementieren oder eine Basisklasse erweitern. Sie müssen die neue Klasse am Typepool registrieren. Diese Registrierung führen Sie in einer Klasse durch, die die Schnittstelle RegisterIF implementiert und in der Option RegisterClass benannt ist. Diese Prozedur müssen Sie durchführen, egal ob Sie einen neuen Dialog oder eine neue Einschränkung oder eine neue Eigenschaft einführen wollen. Die neuen Klassen müssen im Klassenpfad der Engineering-Aktion enthalten sein.
Im Beispiel wird der neue Dialog MyFrame im Paket org.test durch die Klasse MyRegisterClass für die Schnittstelle WorkflowInterface registriert. Um sprachabhängige Beschreibungen zu erhalten, legen Sie zwei Sprachdateien messages.properties und messages_de.properties an. Diese Namen können Sie in der Konfigurationsoberfläche in der Ablaufsteuerung sehen.
Die Sprachdatei für englisch:
org.test.MyFrame=My
own dialog
und deutsch:
org.test.MyFrame=Mein
eigener Dialog
Der Quelltext für MyRegisterClass:
package org.test;
public class MyRegisterClass implements
RegisterIF {
public void execute(Session session) throws M2MException {
// classes
TypePoolInterface
pool = session.getTypePool();
pool.register(WorkflowInterface.class, MyFrame.class);
}
}
11.2 Eigene Optionen
Eigene Optionen können Sie in
der Konfigurationsoberfläche anlegen. Dort können Sie auch den Standardwert,
den Anzeigenamen und eine Beschreibung hinterlegen. Diese Texte sind sprachabhängig
und werden für die Sprache und das Land gespeichert, in dem die Java Virtuelle
Maschine läuft. Der Name der Option sollte mit dem Paketnamen qualifiziert
sein. Sie können Optionen auch im Quelltext der Registerklasse definieren. Die
Registerklasse implementiert die
Schnittstelle RegisterIF und wird in der Option RegisterClass benannt. Auf diese Weise können Sie auch eine Liste möglicher Werte hinterlegen.
Der Quelltext für MyRegisterClass:
package org.test;
public class MyRegisterClass implements
RegisterIF {
public void execute(Session session) throws M2MException {
// options
OptionModelInterface
optionModel = session.getOptionModel();
if (!optionModel.existsOption("org.test.MyOption"))
{
ArrayList<String>
listValue = new ArrayList<String>();
listValue.add("true");
listValue.add("false");
optionModel.setOption("org.test.MyOption", "true", false);
optionModel.addValues("org.test.MyOption", listValue);
}
}
}
Sie können die Anzeigenamen und die Beschreibung von eigenen
Optionen auch mit Sprachdateien durchführen. Die Sprachdatei für englisch:
org.test.MyOption=My
option
org.test.MyOptionDetail=My first own option defined in the register class.
und deutsch:
org.test.MyOption=Meine Option
org.test.MyOptionDetail=Meine erste eigene Option, die in einer Registerklasse
definiert wurde.
Die Modellelemente befinden sich in einem Modell. Die Quellelemente im Quellmodell und die Zielelemente im Zielmodell. Quellmodell und Zielmodell können sich auch überschneiden, dann ist jedoch das Beenden der Modelltransformation nicht gewährleistet, wie in Kapitel 5.1.1. Quellmodell und Zielmodell erwähnt. Ein Modell hat ein Metamodell. Das Metamodell bestimmt, wie ein Modellelement anhand der URI bestimmt werden kann und welche Eigenschaften ein Modellelement unterstützt. Das M2M-SDK unterstützt das Metamodell von Innovator, sowohl die classiX, eXcellence als auch die InnovatorX-Editionen. Desweiteren werden Eclipse UML, XML und DDL unterstützt. Das Metamodell kann nicht vom M2M-SDK bestimmt werden, sondern muss über die Parameter sourceMetaModel und targetMetaModel an der Modelltransformation gesetzt werden.
Sie können weitere Metamodelle zum M2M-SDK hinzufügen, indem Sie die Java-Klasse de.mid.innovator.m2msdk.model.transformation.MetaModel überschreiben und dabei die Namenskonvention einhalten. Der Name des Metamodells darf nur aus Buchstaben und Zahlen bestehen und die Java-Klasse muss im Paket de.mid.innovator.m2msdk.<Name des <Metamodells> sein und als Namen des Namen des Metamodells haben. Sie müssen die Klassen MappingElementBaseImpl und MappingModel überschreiben. Ebenso müssen Sie für die vom Metamodell unterstützten Eigenschaften die Schnittstelle PropertyDescriptorIF implementieren. Wenn Sie neue Eigenschaftstypen einführen wollen, müssen Sie eine Aufzählung anlegen, die die Schnittstelle PropertyTypeIF implementiert. Ihre Klassen und Aufzählungen müssen Sie am TypePool registrieren.
Sie können das M2M-SDK als verteilte Anwendung laufen lassen. Dabei wird die Java Technologie RMI (remote method invocation) verwendet. Im lokalen Betrieb laufen die Dialoge und Clientanwendungen im selben Prozess wie die Serveranwendungen. Dieser Prozess läuft auf dem lokalen Rechner. Das Modell (z.B. das Innovator-Modell in einem Innovator-Repository) läuft üblicherweise auf einem Serverrechner. Bei der verteilten Berechnung laufen die Clientanwendungen in einem Prozess auf dem lokalen Rechner und die Serveranwendungen pro Mappinganwendung MappingApplication in einem Prozess auf einem Serverrechner. Die Verteilung der Anwendungen auf Prozesse und Rechner ist im folgenden Diagramm in Abbildung 5 exemplarisch dargestellt.
Abbildung 5: M2M-SDK im Mehrbenutzerbetrieb als verteilte Anwendung
Der Einsatz der verteilten
Berechnung wird empfohlen, wenn die lokale Rechenleistung ungenügend ist oder
wenn die Netzwerkverbindung in Bezug auf Latenzzeit und Bandbreite zwischen dem
RMI-Server und dem Modell besser ist als zwischen der lokalen Maschine und dem
Modell. Den Rechner, auf dem diese Anwendung läuft, nennen wir den M2M-SDK-Serverrechner.
Der Rechner muss genügend Speicher zur Verfügung haben, um die Prozesse
aufzunehmen. Für jeden Prozess ist mit bis zu 1 Gigabyte Speicherbedarf zu
rechnen. Dadurch ergibt sich eine maximale Anzahl von gleichzeitig laufenden
Modelltransformationen.
Für verteilte Berechnung müssen Sie eine weitere Aktionssequenz konfigurieren, die die M2M-SDK-Serverfabrik auf dem M2M-SDK-Serverrechner startet. Sie müssen die Aktionssequenz auf dem M2M-SDK-Serverrechner ausführen. Ab jetzt kann sich eine Mappinganwendung von einem Clientrechner aus zur M2M-SDK-Serverfabrik verbinden. Die Serverfabrik weist der Mappinganwendung wiederum einen M2M-SDK-Server ServerApplication zu. Die weitere Kommunikation erfolgt ausschließlich zwischen der Mappinganwendung und dem M2M-SDK-Server. Diese Aufrufsequenz sehen Sie in Abbildung 6. Tatsächlich startet die M2M-SDK-Serverfabrik immer einen M2M-SDK-Server im Vorfeld, damit dieser bereit steht, wenn der Aufruf aus der Mappinganwendung ankommt. Da die M2M-SDK-Server automatisch von der M2M-SDK-Serverfabrik gestartet werden, benötigen Sie dafür keine Aktionssequenz.
Abbildung 6: M2M-SDK-Serverfabrik
Um die laufenden M2M-SDK-Server zu überwachen, richten Sie sich eine Aktionssequenz für die Monitoranwendung MonitorApplication ein. In dieser können Sie sehen wieviele M2M-SDK-Server momentan laufen und Sie können sie auch beenden. Normalerweise beenden sich M2M-SDK-Server automatisch wenn die dazugehörende Mappinganwendung sich beendet hat.
Um verteilte Berechnung zu aktivieren, müssen Sie die Option RMIServer für alle Anwendungen setzen. Sie müssen die Optionen RMISourceUser, RMISourcePassword, RMITargetUser, RMITargetPassword, RMITargetRole und RMISourceRole setzen, damit sich der M2M-SDK-Server beim Modell anmelden kann. Außerdem müssen Sie die Sicherheitsrichtlinien in der Datei rmi.policy pflegen, die in der Option RMIPolicy referenziert wird. Der Port, auf der die M2M-SDK-Serverfabrik auf Anfragen lauscht und auch die Portnummern für die M2M-SDK-Server werden in der Option RMIServer gesetzt. Die Einschränkung ist, dass der M2M-SDK-Serverrechner denselben Lizenzserver verwendet, wie jeder Clientrechner. Den Lizenzserver können Sie mit der Option de.mid.innovator.inohost setzen.
Sie können in einer Modelltransformation nach Fehlern suchen, indem Sie die Option DebugMode auf "true", die Option LogLevel auf "Trace" und die Option ShowDialog to “true” setzen. Jedes Mal, wenn die Modelltransformation ausgeführt wird, erscheint nun ein Dialog mit drei Registern. Das erste Register zeigt den Baum der Modelltransformationskonfiguration. Der aktuell ausgeführte Konfigurationseintrag wird hervorgehoben angezeigt. In diesem Register ist es einfach möglich, einen Konfigurationseintrag auszuführen oder hineinzuspringen oder herauszuspringen. Ein weiteres Register zeigt die Variablen an, die durch die Modelltransformation verändert werden. Ein weiteres Register zeigt die Ereignisse als Protokoll an. Sie können die Modelltransformation auch abbrechen. Durch das Beobachten der Variablenwerte nach der Ausführung eines Konfigurationseintrags (z.B. ein Suche des Ziels) können Sie den Erfolg der einzelnen Aufgabe sehen und daraus Rückschlüsse ziehen, was Sie eventuell in der Modelltransformationskonfiguration verändern müssen.
Hartmut Ehrig, Karsten Ehrig, Ulrike Prange and Gabriele Taentzer. Fundamentals of Algebraic Graph Transformation (Monographs in Theoretical Computer Science. An EATCS Series). Springer-Verlag Berlin Heidelberg, 2006
Copyright
© 2012 MID GmbH
07.04.2011
Bei Fragen wenden Sie sich
bitte an unsere Hotline. Telefon: +49 (0)911 96836-222, E-Mail: support@mid.de.
MID GmbH, Kressengartenstraße 10, 90402 Nürnberg
Telefon: +49 (0)911 96836-0, Fax: +49 (0)911 96836-100, E-Mail: info@mid.de, Internet: http://www.mid.de